
1 前言
数据库性能优化,特别是SQL性能优化是程序员的一项基本功。对于常见应用系统,一般最容易出现问题的地方也多在数据库环节。消灭慢SQL,给数据库减负,保证大促期间系统平稳,是我们日常需要做好的任务之一。由于篇幅有限,在这里对关系数据库中SQL性能优化做一些简单的介绍,文中所用术语主要以Mysql数据库为主。
2 SQL执行过程
我们从SQL的执行过程来探寻一下MySQL是如何优化和执行SQL的,如下图:
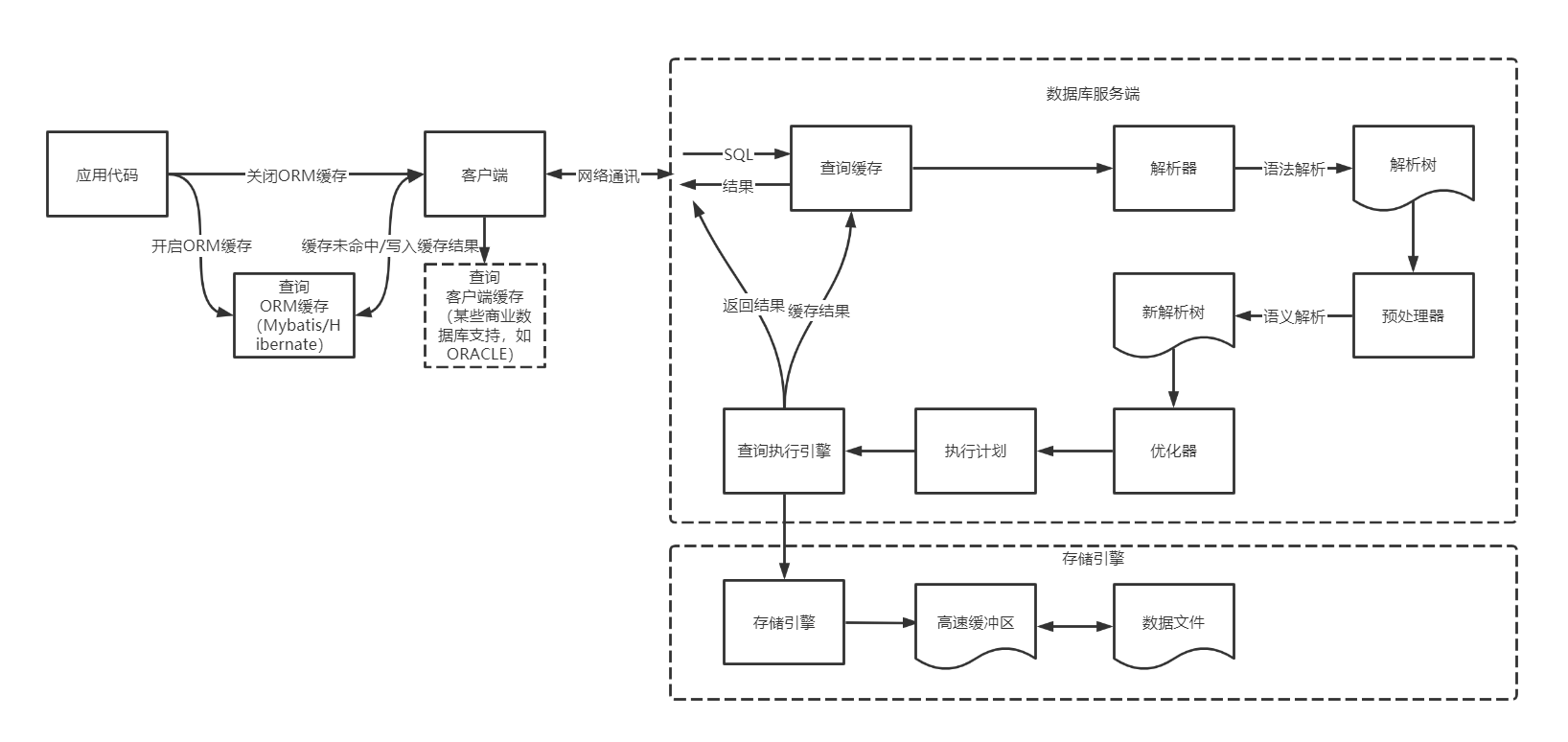
查询缓存:在解析SQL前,如果已开启查询缓存,MySQL会检查SQL是否命中查询缓存,如命中,在检查用户权限后直接返回缓存中的结果。这种情况下,查询不会被解析,也不会重新生成并执行执行计划。命中查询缓存需要SQL语句完全匹配,包括空格和换行等,且要求SQL中不包含随时间或用户变化结果也跟着变化的函数等。查询缓存会带来一些额外的开销,在生产环境中,应该根据实际情况,谨慎开启。 语法解析和预处理:解析器主要检查SQL关键字及顺序位置是否正确等,预处理器检查要查询的数据表和数据列是否存在,用户是否具备访问权限等等。 查询优化:优化器主要进行SQL重写,并根据统计信息和索引情况,评估并生成成本最低的执行计划等。 注1:SQL重写:SQL等价变换,在某些商业数据库中,还包含物化视图重写等步骤。 注2:成本最低:是优化器认为的成本最低,实际中并不一定是成本最低,执行效率最高的执行计划。当优化器评估并采用的执行计划性能较差时,就需要人工干预,来使优化器选用更合理的执行计划。 执行SQL:查询执行引擎根据执行计划给出的指令,逐步调用存储引擎的接口执行并得出结果。存储引擎在访问数据时,会优先从高速缓冲区中访问数据,未命中时,再从磁盘加载数据。
3 影响SQL性能的因素
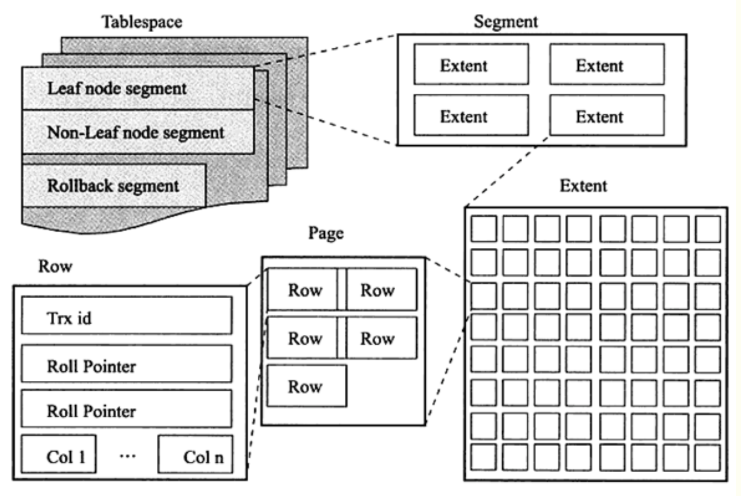
数据量: 如果我们去统计并分析数据库在执行SQL的具体步骤中所花的时间占比,会发现大部分的CPU时间都花在了IO上,特别是磁盘IO。因此访问数据量的多寡会极大的影响SQL的执行效率。 这里的数据量包含数据条数和数据长度两个维度。以磁盘IO为例,不考虑批量IO和预加载机制的情况下,单次IO只能访问一个Page的数据,这个时间基本是固定的。在数据长度固定的情况下,读取的数据条数越多,读取的Page数就越多,产生的IO次数就会越多,总的耗时就越长。在读取数据条数固定的情况下,每行数据的长度越大,单个Page所能存放的行数就越少,读取的Page数据就越多,所产生的IO次数也就越多,总的耗时就越长。 由于数据量对于SQL性能的影响非常大,所以我们常常利用定期归档来减少表的数据量,访问数据时采用高效索引快速过滤数据,使用limit以提前中止SQL执行等方式来减少访问的数据量,最终达成减少IO次数,缩短执行时长的目标。 注1:磁盘IO:也叫物理IO,是从磁盘加载数据到高速缓冲区。与之对应的为逻辑IO,是从高速缓冲区,也就是内存中读取并解析数据。机械硬盘时代,物理IO的速度是逻辑IO速度的万分之一到千分之一。产生一次物理IO的同时,也将必然产生一次逻辑IO。 注2:Page:关系数据库默认一般为8K~16K,Innodb默认16K,5.7版本支持32K和64K。逻辑结构如下图。 注3:索引:索引可以近似理解为字段少一点,行数据长度小一点的瘦表,类似于目录。由于单个Page中所能存储的索引条目数量远大于存储表中的行数据的条数,因此索引占用的总的Page数一般会比表少很多,而且由于索引数据会被高频次访问,因此索引数据一般会常驻在高速缓冲区的LRU链表中,不会被刷掉。这样,通过索引查询,就基本都变成了内存查询,再加上索引高的选择性,几乎可以过滤掉绝大多数数据,减少了回表访问的数据量,因此通过索引查询的效率一般远远大于全表扫描(当然也有很多全表扫描更快的例外情况,这里就不展开讨论了)
表结构:表结构决定了数据怎么存储,数据之间如何关联,表中包含哪些索引等等。合理的表结构能够极大减少IO次数,降低数据访问量,尤其是高效的索引。必要的反范式化设计,减少表关联,以空间换时间,常常能够带来意想不到的效果。
应用代码:代码的好坏,决定了应用是否合理地访问了必要的数据,是否合理地使用了数据库连接资源等等。
执行计划:大多数情况下,优化器都会采取最优或相对合理的执行计划。好的执行计划可以极大地减小IO次数,提高SQL执行效率。执行计划和SQL的写法,表的个数,表的数据量,索引情况,统计信息等信息密切相关。分析执行计划也是调优某个具体SQL时需要做的第一步。
数据库负载:当数据库压力特别大时,CPU和磁盘使用率极高,这时即使是非常高效的主键查询单条数据,也可能会非常慢,此时整个库的性能会呈现指数级恶化。反之,有些较慢的SQL,在数据库毫无压力的时候,性能也往往可以令人接受。一些高频SQL,或者某些IO较多的SQL(如百万以上级别的全表扫描),可以在很短时间内可拖垮整个数据库,碰到这种情况时,我们常常会联系DBA杀掉这些慢SQL来恢复环境。
资源争用:热点数据,锁争用,闩锁/互斥争用等等也会影响SQL性能。最常见的如死锁,当数据库中存在大量死锁时,会造成数据库性能的急剧下降。
数据库版本:一般情况下,越高版本的数据库其优化器越智能,访问数据的性能也往往越好,功能也更加齐全和完备。不过,没有经过长时间检验的版本也往往存在各种各种的bug,因此在选型版本时,要兼顾性能和稳定性,以及开发人员的技能和熟悉度,在公司提供支持的版本中,尽可能选用较高的版本。 数据库参数配置:数据库的参数对性能具有很大影响,如缓存是否开启,高速缓冲区大小,排序区大小等等。一般可以在预发数据库查看相关参数(线上环境需要联系DBA查看),必要时联系DBA进行相关参数的调整,调整前,做好评估和测试,谨慎操作。
硬件规格:这个就不解释了。当其他角度的优化做完后,性能依然不能满足要求时,联系DBA进行硬件规格的扩容或者增加从库。
4 性能优化从哪个阶段开始入手
以瀑布模型来讨论,在越早的阶段进行性能优化效果越好,代价也越小。反之,代价越大,效果越差。 因此在设计阶段就应该做好表设计和数据存储设计等,拙劣的表设计,无论后期如何进行SQL优化和增加索引,可能效果也往往不尽如人意。在开发代码前就应该知道如何去访问库中的数据,通过什么索引,如何关联结果集,执行计划应该是什么样的。而不是等到上线后,线上出现问题时才开始排查和进行优化。
5 性能优化如何做
SQL优化的第一性原理:优化IO、优化CPU 来减少资源争用。当IO压力较大时,CPU使用率也会特别高,因此优化IO是优化SQL的第一要因。
5.1 需要具备的基本知识点 SQL执行过程:1)软解析、硬解析 ;2)物理IO、逻辑IO;3)事务、隔离级别、MVCC;4)快照读、当前读;5)锁机制;6)执行计划、索引、排序、HINT。由于篇幅关系,这里不一一介绍,仅针对执行计划做简单描述,其他知识点请自行查阅相关资料。
5.2 执行计划 调优SQL时,一般会先尝试获取SQL执行计划,通过分析执行计划,评估SQL性能。 执行计划的获取方法:使用explain命令

执行计划中各关键字的含义:
1、id:标识sql执行顺序,按照id从大到小顺序执行,id相同时按照从上到下顺序执行
2、select_type:查询类型,包括: SIMPLE:最简单的查询SQL,不包含任何子查询或者UNION PRIMARY:子查询之外的主SQL、或者UNION中的第一个SELECT SUBQUERY:SELECT或WHERE语句中的子查询 DERIVED:FROM中的子查询 UNION:UNION之后的SELECT UNION RESULT:UNION的结果 INSERT:INSERT语句 UPDATE:UPDATE语句 DELETE:DELETE语句
3、table:访问的表名或表别名
4、type:访问行的方式类型,一般ALL效率最低,NULL最高: ALL:全表扫描,效率最低 INDEX:索引全扫描,遍历整个索引树。ALL属于特殊的索引全扫描,遍历整个主键索引 RANGE:索引范围扫描,返回匹配值域的行。 REF:非唯一性索引扫描,返回匹配某个单独值的所有行。一般是指多列的唯一索引中的某一列 EQ_REF:唯一性索引扫描,表中只有一条记录与之匹配,一般为表关联中从表的关联键-主键 CONST、SYSTEM:主要针对查询中有常量的情况,如果结果只有一行会变成system NULL:既不走表,也不走索引
4、possible_keys:预估可使用的索引,实际中不一定会使用。为空表名没有可用的索引
5、key:实际使用的索引(如果为NULL,则没有使用索引)
6、key_len:索引条目长度。从表定义估算出来的。理论上索引长度越短,一个page所包含的索引条目就会越多,检索数据所需要访问的page数量可能就会越少,对应IO次数就会减少
7、ref:谓词的关联信息,可能为 :null、const(常量)、关联的谓词列名
8、rows:预估结果集的条数,根据统计信息估算出来的,不一定完全准确
9、Extra:其他额外信息: Using filesort:无法利用索引避免排序时出现,会产生排序,但不一定会产生实际的文件排序。 Using temporary:使用临时表保存中间结果,常见于order by 和 group by。 Using index:使用了覆盖索引(Covering Index),避免了访问表的数据行,效率高;如果同时出现Using where,表明索引被用来执行索引键值的查找;如果没有同时出现Using where,表明索引用来读取数据而非执行查找动作。 Using join buffer:使用了链接缓存。 eq_ref:唯一性索引扫描,表中只有一条记录与之匹配。 Impossible WHERE:where子句的值总是false,不能用来获取任何元祖。 select tables optimized away:在没有group by子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段在进行计算,查询执行计划生成的阶段即可完成优化。 distinct:优化distinct操作,在找到第一个匹配的元祖后即停止找同样值得动作。 注1:在某些商业数据库中,可以在获取执行计划的同时,还可以查看SQL相关的统计信息,如物理IO和逻辑IO次数等,也可以通过一些工具获取数据库在某段时间内的SQL解析命中缓存概率,等待事件,闩锁争用等相关信息。Mysql中也可以通过infomation_schama获取一些性能相应的统计信息。
5.3 一个栗子 某SQL:
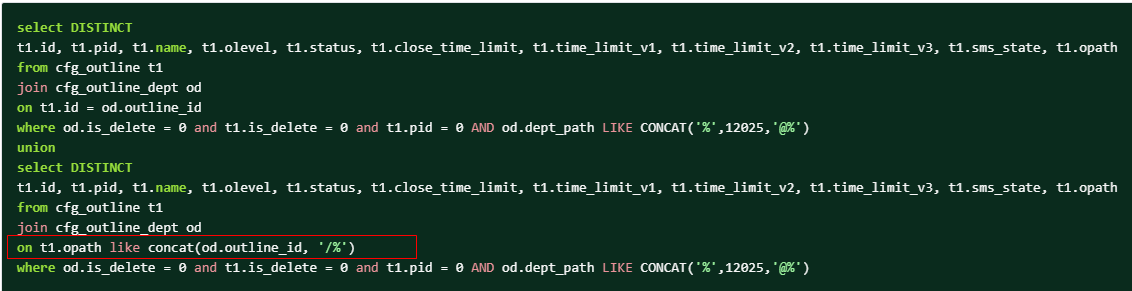
问题分析:由于在从表的关联条件上增加函数计算,导致无法使用索引,进而产生了类似于嵌套全表扫描的执行计划:即针对于驱动表的每一条数据,都会进行一次从表的全表扫描,产生了大量多余的IO。Mysql 5.5版本该执行计划被优化为Block nested loop:即把驱动表的结果集存放入join buffer中,访问从表并逐条匹配驱动表的数据,最后返回匹配结果。执行计划如下图所示,版本Mysql 5.6:

注1:Block nested loop中从表的访问次数,取决于join buffer size的大小和驱动表的结果集大小,当驱动表的结果集能完全存放入join buffer size时,从表只扫描一次,当只能存放十分之一时,从表需要扫描十次,以此类推。 优化办法:把从表上关联字段上的函数计算挪到驱动表上,从而能够利用从表关联字段上的索引,降低单次访问从表的IO量和时长。
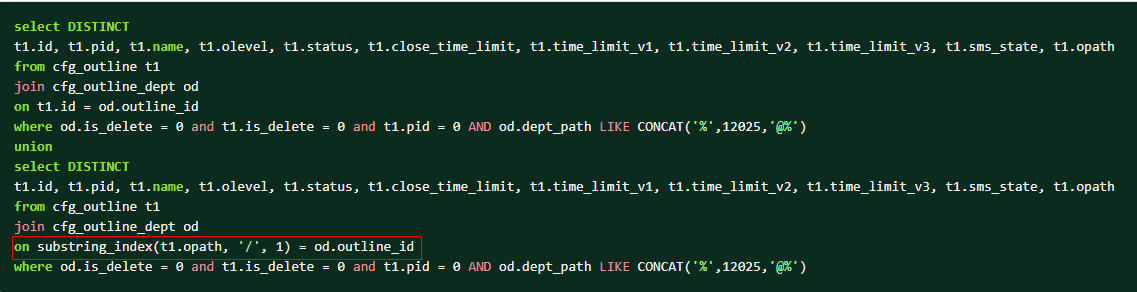

实际效果:整个SQL性能提升了约20倍。
6 常见调优基本原则
调优需要从整个数据库或应用的全局出发,而不是单一SQL的角度。 从执行频率高的SQL开始优化,而不是低频率的“大”SQL或慢SQL。因为一但高频SQL出问题,对数据库影响更大,更容易拖慢甚至拖垮整个库。 最快速的过滤掉数据,让数据库尽可能少的去做IO操作。高选择性的索引通常是一个很好的实践手段。 尽可能在每个查询语句中加上limit,让SQL尽可能早的中止,以防止在某些被忽略的场景,或某些bug引发大数据量的查询,导致数据库压力上升,或应用服务器端OOM。 在满足性能要求时,能执行批量操作尽量批量操作,如批量插入,多个SQL合并成一个,目的是为了减少IO次数(包括物理IO和逻辑IO,网络IO)。 不要过度复用SQL,以避免造成不必要的表关联和数据查询。过于动态的SQL,常常会给SQL调优带来很多困扰。 写SQL时要评估好执行计划是否合理,是否存在索引不合理,索引失效等场景(如,数据偏斜、函数计算、隐式转换、字符集问题等等)。 排序操作会耗费大量CPU资源。尤其是当排序的结果集过大,不能在内存中完成排序时(INNODB默认的sort_buffer_size只有1M大小),会引发磁盘多路归并排序,产生大量的磁盘IO,因此尽可能避免排序 表关联通常是代价比较大,应充分平衡应用服务器端和数据库端的压力,基于应用服务器更好扩展,在可行的前提下,尽可能的把关联操作放在应用端。 Mysql优化器对子查询的优化力度一般,容易出现问题,尽可能避免使用复杂的子查询,或者尽量不使用子查询。 当出现因统计信息不准确导致优化器选择了较差的执行计划时,除了采用改写 SQL,增加HINT提示,固定表关联顺序等手段,必要时可以采用手动分析表来重新收集统计信息(当数据变化超过表数据10%时,会自动触发表的分析操作)。
7 总结
优化时机:《黄帝内经》有云:“上工治未病,不治已病,此之谓也”。《扁鹊见蔡桓公》:“疾在腠理,汤熨之所及也;在肌肤,针石之所及也;在肠胃,火齐之所及也;在骨髓,司命之所属,无奈何也。今在骨髓,臣是以无请也。”尽可能早的考虑清楚性能问题,而不是出现问题时才开始调优。同样,开发前就要能对将要写出的SQL性能和执行计划做出清晰的预测和评估,画竹前做到心中有竹。 优化方向:做SQL性能调优时,90%甚至95%以上的优化,都是想办法让数据库减少IO次数。站在这个的角度来评估具体的优化方案,必能事半功倍。 优化原则:抓大放小,深入分析问题根因,达到预期即可,不要过度优化。此外,不同的场景和实际情况,优化策略所能产生的效果可能会有很大差别,以原理分析作为指导,以实际测试作为依据,不要盲目教条使用常见的优化建议,如select*性能好于select 1等等。
8 引经据典-参考文献
https://zhuanlan.zhihu.com/p/297990759?utm_source=wechat_session
https://www.cnblogs.com/wilburxu/p/9429014.html