
LoadingCache
LoadingCache主要实现的功能:
A builder of {@link LoadingCache} and {@link Cache} instances having any combination of thefollowing features:
- automatic loading of entries into the cache(自动加载项目到缓存中)
- least-recently-used eviction when a maximum size is exceeded(LRU算法)
- time-based expiration of entries, measured since last access or last write(失效时间)
- keys automatically wrapped in {@code WeakReference}(包装key)
- values automatically wrapped in {@code WeakReference} or {@code SoftReference}(包装value)
- notification of evicted (or otherwise removed) entries(失效通知)
- accumulation of cache access statistics(统计信息)
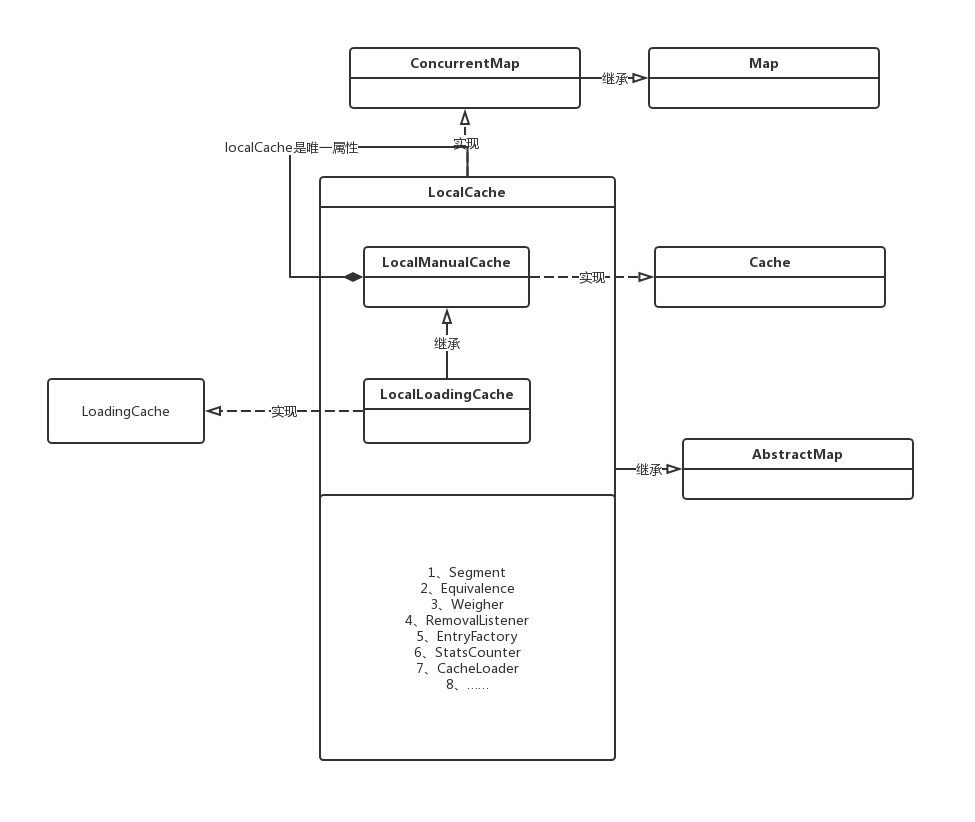
对于构造LocalCache最直接的两个相关类是LocalManualCache和LocalLoadingCache。
LocalManualCache和LocalLoadingCache
顺着构造源码看下
/**
* 1、我们在代码中通过调用此处的build方法,调用LocalCache.LocalLoadingCache内部类生成LocalCache对象
*/
public <K1 extends K, V1 extends V> LoadingCache<K1, V1> build(
CacheLoader<? super K1, V1> loader) {
checkWeightWithWeigher();
return new LocalCache.LocalLoadingCache<K1, V1>(this, loader);
}
/**
* 2、调用LocalLoadingCache的超类构造LocalCache
*/
static class LocalLoadingCache<K, V>
extends LocalManualCache<K, V> implements LoadingCache<K, V> {
LocalLoadingCache(CacheBuilder<? super K, ? super V> builder,
CacheLoader<? super K, V> loader) {
super(new LocalCache<K, V>(builder, checkNotNull(loader)));
}
}
/**
* 将构造好的LocalManualCache赋值给LocalManualCache中属性
*/
static class LocalManualCache<K, V> implements Cache<K, V>, Serializable {
final LocalCache<K, V> localCache;
LocalManualCache(CacheBuilder<? super K, ? super V> builder) {
this(new LocalCache<K, V>(builder, null));
}
private LocalManualCache(LocalCache<K, V> localCache) {
this.localCache = localCache;
}
}
那么这个LoadingCache到底是什么作用呢,其实就是LocalCache对外暴露了实现的方法,所有暴露的方法都是实现了这个接口,LocalLoadingCache就是实现了这个接口,下边是部分源码:
@Override
public V get(K key) throws ExecutionException {
return localCache.getOrLoad(key);
}
@Override
public V getUnchecked(K key) {
try {
return get(key);
} catch (ExecutionException e) {
throw new UncheckedExecutionException(e.getCause());
}
}
@Override
public ImmutableMap<K, V> getAll(Iterable<? extends K> keys) throws ExecutionException {
return localCache.getAll(keys);
}
@Override
public void refresh(K key) {
localCache.refresh(key);
}
@Override
public final V apply(K key) {
return getUnchecked(key);
}
// Serialization Support
private static final long serialVersionUID = 1;
@Override
Object writeReplace() {
return new LoadingSerializationProxy<K, V>(localCache);
}
特殊的是它是LocalCache的内部静态类,这个LocalLoadingCache内部静态类只是降低了LocalCache的复杂度,它是完全独立于LocalCache的。下边是我们使用的方法都是LocalCache接口的方法
说完了LocalLoadingCache我们看下LocalManualCache的作用,LocalManualCache是LocalLoadingCache的父类,LocalManualCache实现了Cache,所以LocalManualCache具有了所有Cache的方法,LocalLoadingCache是继承自LocalManualCache同样获得了Cache的所有方法,但是LocalLoadingCache可以选择的重载LocalManualCache中的方法,这样的设计有很大的灵活性;guava cache的内部实现用的LocalCache,但是对外暴露的是LocalLoadingCache,很好隐藏了细节,总结来说
1、LocalManualCache实现了Cache,具有了所有cache方法。
2、LocalLoadingCache实现了LoadingCache,具有了所有LoadingCache方法。
3、LocalLoadingCache继承了LocalManualCache,那么对外暴露的LocalLoadingCache的方法既有自身需要的,又有cache应该具有的。
4、通过LocalLoadingCache和LocalManualCache的父子关系实现了LocalCache的细节。
Guava Cache到底是如何进行缓存的
我们现在通过类图和源码的各种继承关系理清了这两个LocalLoadingCache和LocalManualCache的重要关系,下边我们再继续深入,通过我们常用的get方法进入:
/**
* LocalLoadingCache中的get方法,localCache是父类LocalManualCache的
*/
@Override
public V get(K key) throws ExecutionException {
return localCache.getOrLoad(key);
}
/**
* 这个get和getOrLoad是AccessQueue中的方法,AccessQueue是何方神圣呢,我们通过类图梳理一下他们的关系
*/
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
int hash = hash(checkNotNull(key));
return segmentFor(hash).get(key, hash, loader);
}
V getOrLoad(K key) throws ExecutionException {
return get(key, defaultLoader);
}

很明显这是队列,这两个队列的作用如下
WriteQueue:按照写入时间进行排序的元素队列,写入一个元素时会把它加入到队列尾部。
AccessQueue:按照访问时间进行排序的元素队列,访问(包括写入)一个元素时会把它加入到队列尾部。
在这里就会涉及到segement的概念了,我们先把关系理清楚,首先看ConcurrentHashMap的图示,这样有助于我们理解:
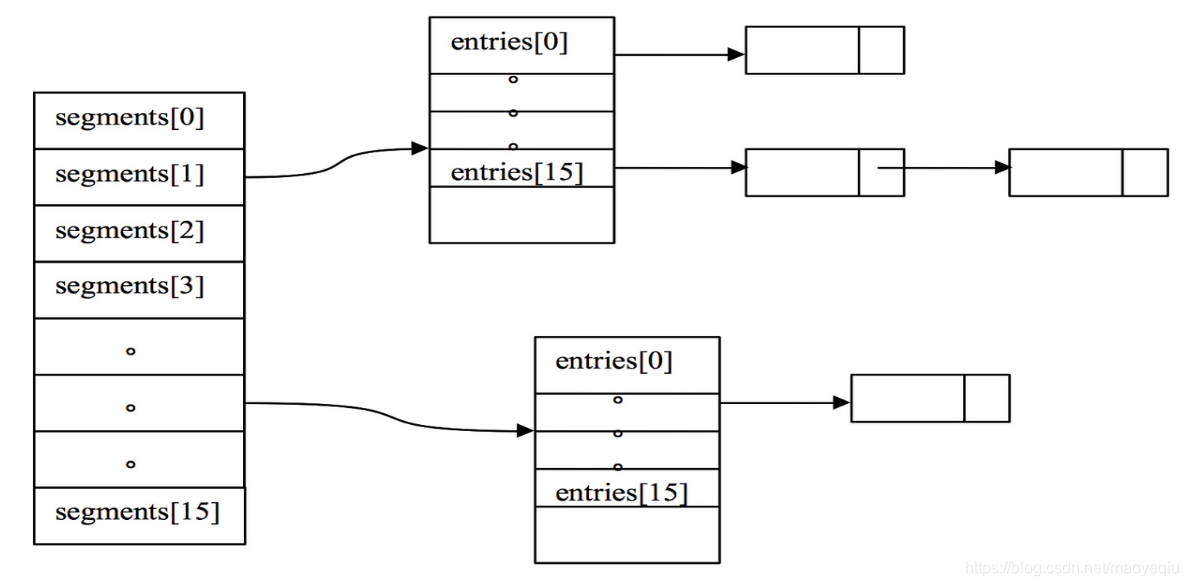
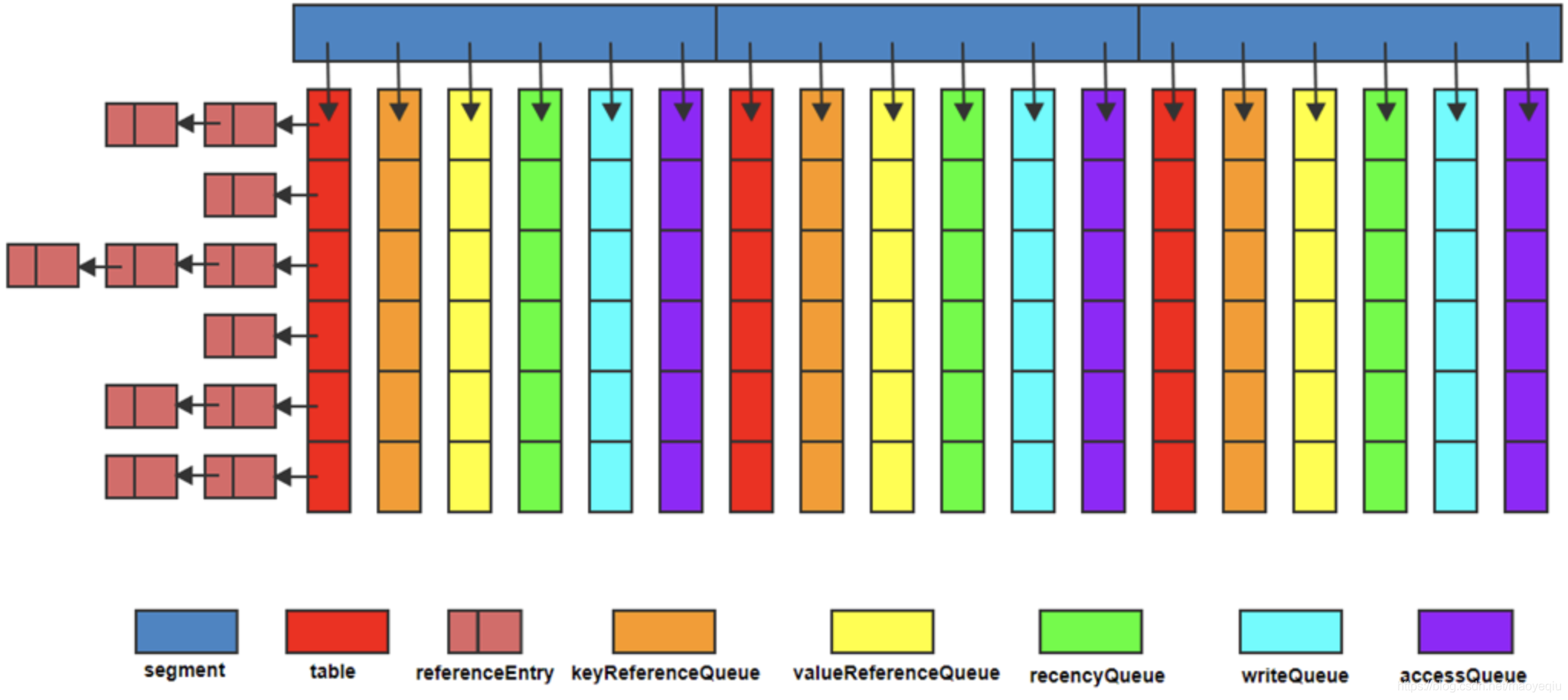
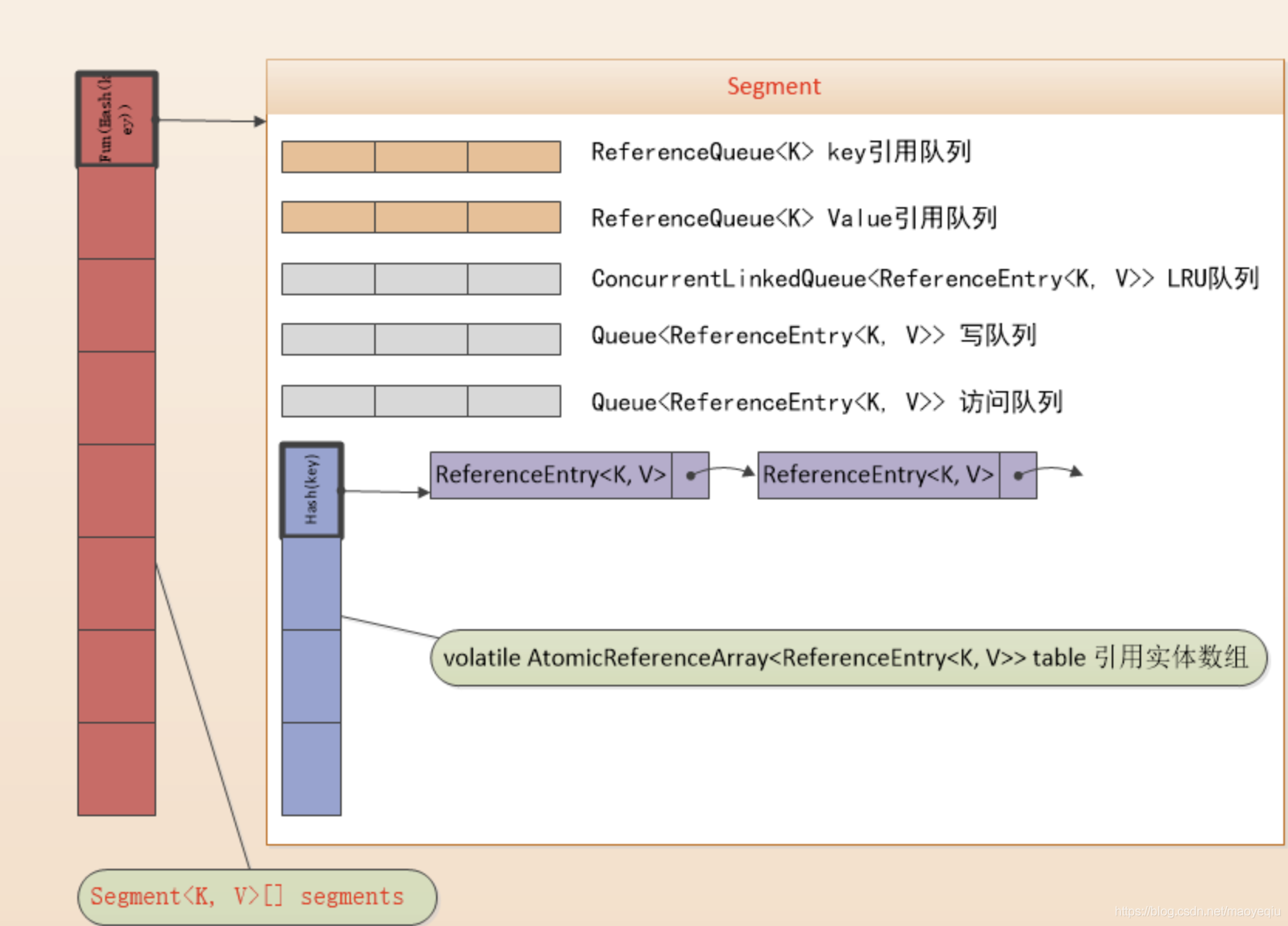
LocalCache类似ConcurrentHashMap采用了分段策略,通过减小锁的粒度来提高并发,LocalCache中数据存储在Segment[]中,每个segment又包含5个队列和一个table,这个table是自定义的一种类数组的结构,每个元素都包含一个ReferenceEntry<k,v>链表,指向next entry。这些队列,前2个是key、value引用队列用以加速GC回收,后3个队列记录用户的写记录、访问记录、高频访问顺序队列用以实现LRU算法。AtomicReferenceArray是JUC包下的Doug Lea老李头设计的类:一组对象引用,其中元素支持原子性更新。这种实现比ConcurrentHashMap要复杂的多,除了多了5个引用队列之外,并且采用了ReferenceEntry的方式,引用数据存储接口,默认强引用,对应的类图为:
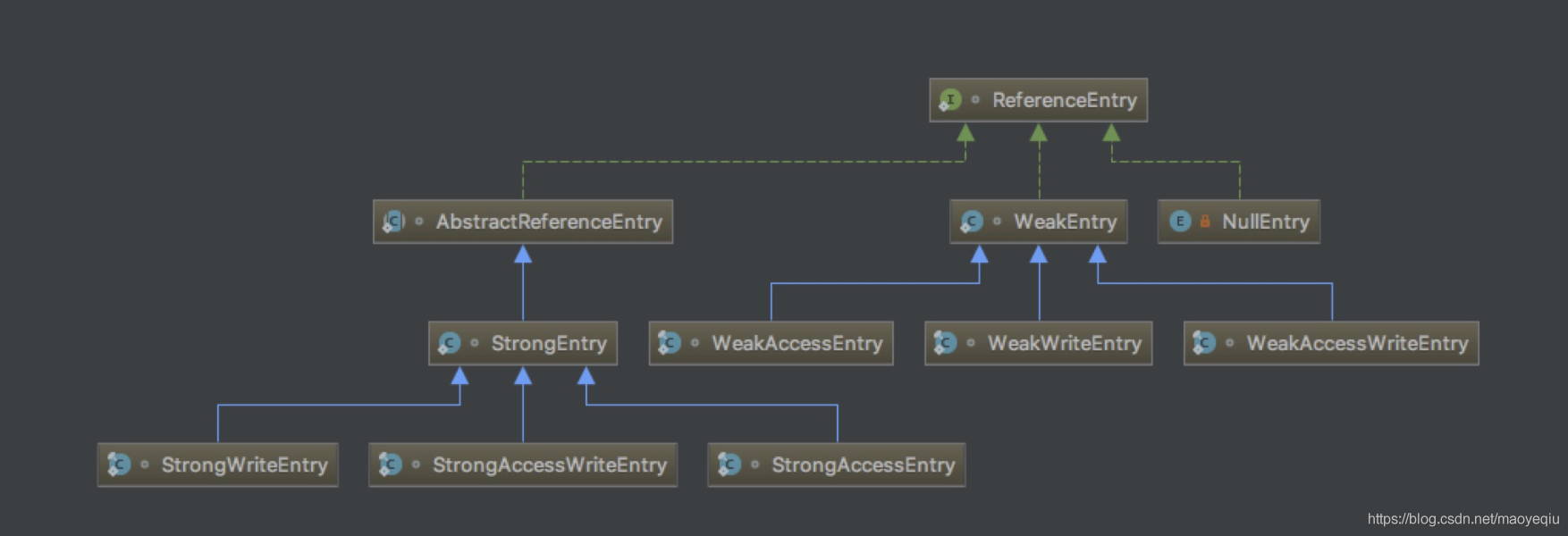
我们来看下ReferenceEntry接口的代码,具备了一个Entry所需要的元素
interface ReferenceEntry<K, V> {
/**
* Returns the value reference from this entry.
*/
ValueReference<K, V> getValueReference();
/**
* Sets the value reference for this entry.
*/
void setValueReference(ValueReference<K, V> valueReference);
/**
* Returns the next entry in the chain.
*/
@Nullable
ReferenceEntry<K, V> getNext();
/**
* Returns the entry's hash.
*/
int getHash();
/**
* Returns the key for this entry.
*/
@Nullable
K getKey();
/*
* Used by entries that use access order. Access entries are maintained in a doubly-linked list.
* New entries are added at the tail of the list at write time; stale entries are expired from
* the head of the list.
*/
/**
* Returns the time that this entry was last accessed, in ns.
*/
long getAccessTime();
我们继续看get方法,全流程看
public V get(K key) throws ExecutionException {
return localCache.getOrLoad(key);
}
V getOrLoad(K key) throws ExecutionException {
return get(key, defaultLoader);
}
/**
* 1、寻找对应的segment
* 2、寻找对应table中的元素
*/
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
//这里对哈希再哈希(Wang/Jenkins方法,为了进一步降低冲突)的细节暂时不讲,重点关注后面的get方法
int hash = hash(checkNotNull(key));
//根据hash找到对应的那个segment
return segmentFor(hash).get(key, hash, loader);
}
/**
* segmentFor算法
*/
Segment<K, V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
/**
* 1、获取对应的对象
* 2、recordRead记录读取过
* 3、重置刷新
*/
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
//key和loader不能为null(空指针异常)
checkNotNull(key);
checkNotNull(loader);
try {
//count保存的是该sengment中缓存的数量,如果为0,就直接去载入
if (count != 0) { // read-volatile
// don't call getLiveEntry, which would ignore loading values
/**
* 看标记1
*/
ReferenceEntry<K, V> e = getEntry(key, hash);
//e != null说明缓存中已存在
if (e != null) {
long now = map.ticker.read();
/**
* getLiveValue在entry无效、过期、正在载入都会返回null,如果返回不为空,就是正常命中
* 主要看是否存活,看标记2
*/
V value = getLiveValue(e, now);
if (value != null) {
/**
* 看标记3
*/
recordRead(e, now);
//性能统计
statsCounter.recordHits(1);
//根据用户是否设置距离上次访问或者写入一段时间会过期,进行刷新或者直接返回
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference<K, V> valueReference = e.getValueReference();
if (valueReference.isLoading()) {
//如果正在加载中,等待加载完成获取
return waitForLoadingValue(e, key, valueReference);
}
}
}
/**
* 如果不存在或者过期,就通过loader方法进行加载
* 看标记4
*/
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error) cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
}
throw ee;
} finally {
//清理。通常情况下,清理操作会伴随写入进行,但是如果很久不写入的话,就需要读线程进行完成
//那么这个“很久”是多久呢?还记得前面我们设置了一个参数DRAIN_THRESHOLD=63吧
//而我们的判断条件就是if ((readCount.incrementAndGet() & DRAIN_THRESHOLD) == 0)
//条件成立,才会执行清理,也就是说,连续读取64次就会执行一次清理操作
//具体是如何清理的,后面再介绍,这里仅关注核心流程
postReadCleanup();
}
}
/**
* 标记1
*/
@Nullable
ReferenceEntry<K, V> getEntry(Object key, int hash) {
// hash链表,标记1.0
for (ReferenceEntry<K, V> e = getFirst(hash); e != null; e = e.getNext()) {
if (e.getHash() != hash) {
continue;
}
// hash值相同的,接下来找key值也相同的ReferenceEntry
K entryKey = e.getKey();
if (entryKey == null) {
/**
* 看标记1.1
*/
tryDrainReferenceQueues();//线程安全的清除搜集到的entries,使用lock机制。
continue;
}
if (map.keyEquivalence.equivalent(key, entryKey)) {
return e;
}
}
return null;
}
/**
* 标记1.1
* Cleanup collected entries when the lock is available.
*/
void tryDrainReferenceQueues() {
/**
* 看标记1.1.1
*/
if (tryLock()) {
try {
/**
* 看标记1.1.2
*/
drainReferenceQueues();
} finally {
unlock();
}
}
}
/**
*标记1.1.1
*/
public boolean tryLock() {
return sync.nonfairTryAcquire(1);
}
/**
* 标记1.1.2
*/
@GuardedBy("this")
void drainReferenceQueues() {
if (map.usesKeyReferences()) {
drainKeyReferenceQueue();
}
if (map.usesValueReferences()) {
drainValueReferenceQueue();
}
}
/**
* 在segment的keyReferenceQueue的队列中排空队列,满足null的情况执行
*/
@GuardedBy("this")
void drainKeyReferenceQueue() {
Reference<? extends K> ref;
int i = 0;
while ((ref = keyReferenceQueue.poll()) != null) {
@SuppressWarnings("unchecked")
ReferenceEntry<K, V> entry = (ReferenceEntry<K, V>) ref;
map.reclaimKey(entry);
if (++i == DRAIN_MAX) {
break;
}
}
}
/**
* 找到entry对应的元素,相当于每一个元素都要判断一下是否要移除
*/
void reclaimKey(ReferenceEntry<K, V> entry) {
int hash = entry.getHash();
segmentFor(hash).reclaimKey(entry, hash);
}
/**
* Removes an entry whose key has been garbage collected.
*/
boolean reclaimKey(ReferenceEntry<K, V> entry, int hash) {
//加锁,每一个元素都要判断一下
lock();
try {
int newCount = count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
if (e == entry) {
++modCount;
ReferenceEntry<K, V> newFirst = removeValueFromChain(
first, e, e.getKey(), hash, e.getValueReference(), RemovalCause.COLLECTED);
/**
* write-volatile
*/
newCount = this.count - 1;
table.set(index, newFirst);
this.count = newCount; // write-volatile
return true;
}
}
return false;
} finally {
unlock();
postWriteCleanup();
}
}
/**
* 至此元素移除
*/
@GuardedBy("this")
@Nullable
ReferenceEntry<K, V> removeValueFromChain(ReferenceEntry<K, V> first,
ReferenceEntry<K, V> entry, @Nullable K key, int hash, ValueReference<K, V> valueReference,
RemovalCause cause) {
enqueueNotification(key, hash, valueReference, cause);
writeQueue.remove(entry);
accessQueue.remove(entry);
if (valueReference.isLoading()) {
valueReference.notifyNewValue(null);
return first;
} else {
return removeEntryFromChain(first, entry);
}
}
/**
* 标记2
* key和value为空的都会删除
* 然后判断是否过期
*/
V getLiveValue(ReferenceEntry<K, V> entry, long now) {
if (entry.getKey() == null) {
tryDrainReferenceQueues();
return null;
}
V value = entry.getValueReference().get();
if (value == null) {
tryDrainReferenceQueues();
return null;
}
/**
* 看标记2.1
*/
if (map.isExpired(entry, now)) {
tryExpireEntries(now);
return null;
}
return value;
}
/**
* 标记2.1
* 是哪种过期方式
* 先判断访问过期,再是写入过期,不管是那个都会让他过期
*/
boolean isExpired(ReferenceEntry<K, V> entry, long now) {
checkNotNull(entry);
if (expiresAfterAccess()
&& (now - entry.getAccessTime() >= expireAfterAccessNanos)) {
return true;
}
if (expiresAfterWrite()
&& (now - entry.getWriteTime() >= expireAfterWriteNanos)) {
return true;
}
return false;
}
/**
* 标记3
*/
void recordRead(ReferenceEntry<K, V> entry, long now) {
if (map.recordsAccess()) {
entry.setAccessTime(now);//设置元素当前访问时间
}
recencyQueue.add(entry);
}
/**
* 标记1.0
* AtomicReferenceArray 可以确保原子的更新引用的元素。
* 为给定的hash值返回第一个entry节点.
*/
ReferenceEntry<K, V> getFirst(int hash) {
// 复制到线程安全的数组中,形成一个快照,确保读的时候,数据一致性。只会读取这个域一次。
// 此外,这样子可以提供读对于整个table的影响,因为全局的table并不会锁住。(猜测)
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
return table.get(hash & (table.length() - 1));
}
/**
* 标记4
*/
V lockedGetOrLoad(K key, int hash, CacheLoader<? super K, V> loader)
throws ExecutionException {
ReferenceEntry<K, V> e;
ValueReference<K, V> valueReference = null;
LoadingValueReference<K, V> loadingValueReference = null;
boolean createNewEntry = true;
/**
* 先进性加锁
*/
lock();
try {
// re-read ticker once inside the lock
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count - 1;
//当前segment下的HashTable
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
//这里也是为什么table的大小要为2的幂(最后index范围刚好在0-table.length()-1)
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
//在链表上查找
for (e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
valueReference = e.getValueReference();
//如果正在载入中,就不需要创建,只需要等待载入完成读取即可
if (valueReference.isLoading()) {
createNewEntry = false;
} else {
V value = valueReference.get();
// 被gc回收(在弱引用和软引用的情况下会发生)
if (value == null) {
enqueueNotification(entryKey, hash, valueReference, RemovalCause.COLLECTED);
} else if (map.isExpired(e, now)) {
// 过期
enqueueNotification(entryKey, hash, valueReference, RemovalCause.EXPIRED);
} else {
//存在并且没有过期,更新访问队列并记录命中信息,返回value
recordLockedRead(e, now);
statsCounter.recordHits(1);
// we were concurrent with loading; don't consider refresh
return value;
}
// 对于被gc回收和过期的情况,从写队列和访问队列中移除
// 因为在后面重新载入后,会再次添加到队列中
writeQueue.remove(e);
accessQueue.remove(e);
this.count = newCount; // write-volatile
}
break;
}
}
if (createNewEntry) {
//先创建一个loadingValueReference,表示正在载入
loadingValueReference = new LoadingValueReference<K, V>();
if (e == null) {
//如果当前链表为空,先创建一个头结点
e = newEntry(key, hash, first);
e.setValueReference(loadingValueReference);
table.set(index, e);
} else {
e.setValueReference(loadingValueReference);
}
}
} finally {
//解锁,放在finally
unlock();
//执行清理
postWriteCleanup();
}
/**
* 创建新的元素
*/
if (createNewEntry) {
try {
// Synchronizes on the entry to allow failing fast when a recursive load is
// detected. This may be circumvented when an entry is copied, but will fail fast most
// of the time.
synchronized (e) {
/**
* 看标记4.1
* 异步加载
*/
return loadSync(key, hash, loadingValueReference, loader);
}
} finally {
//记录未命中
statsCounter.recordMisses(1);
}
} else {
// 等待加载进来然后读取即可
return waitForLoadingValue(e, key, valueReference);
}
}
/**
* 标记4.1
*/
V loadSync(K key, int hash, LoadingValueReference<K, V> loadingValueReference,
CacheLoader<? super K, V> loader) throws ExecutionException {
/**
* 这里通过我们重写的load方法,根据key,将value载入
* 看标记4.1.1
*/
ListenableFuture<V> loadingFuture = loadingValueReference.loadFuture(key, loader);
/**
* 看标记4.1.2
*/
return getAndRecordStats(key, hash, loadingValueReference, loadingFuture);
}
/**
* 标记4.1.1
* 调用服务加值
*/
public ListenableFuture<V> loadFuture(K key, CacheLoader<? super K, V> loader) {
try {
stopwatch.start();
/**
* 一致性处理
*/
V previousValue = oldValue.get();
if (previousValue == null) {
/**
* 调用服务加载数据
*/
V newValue = loader.load(key);
return set(newValue) ? futureValue : Futures.immediateFuture(newValue);
}
ListenableFuture<V> newValue = loader.reload(key, previousValue);
if (newValue == null) {
return Futures.immediateFuture(null);
}
// To avoid a race, make sure the refreshed value is set into loadingValueReference
// *before* returning newValue from the cache query.
return Futures.transform(newValue, new Function<V, V>() {
@Override
public V apply(V newValue) {
LoadingValueReference.this.set(newValue);
return newValue;
}
});
} catch (Throwable t) {
ListenableFuture<V> result = setException(t) ? futureValue : fullyFailedFuture(t);
if (t instanceof InterruptedException) {
Thread.currentThread().interrupt();
}
return result;
}
}
/**
* 标记4.1.2
* 等待载入,并记录载入成功或失败
*/
V getAndRecordStats(K key, int hash, LoadingValueReference<K, V> loadingValueReference,
ListenableFuture<V> newValue) throws ExecutionException {
V value = null;
try {
value = getUninterruptibly(newValue);
if (value == null) {
throw new InvalidCacheLoadException("CacheLoader returned null for key " + key + ".");
}
//性能统计信息记录载入成功
statsCounter.recordLoadSuccess(loadingValueReference.elapsedNanos());
//这个方法才是真正的将缓存内容加载完成(当前还是loadingValueReference,表示isLoading)
storeLoadedValue(key, hash, loadingValueReference, value);
return value;
} finally {
if (value == null) {
statsCounter.recordLoadException(loadingValueReference.elapsedNanos());
removeLoadingValue(key, hash, loadingValueReference);
}
}
}
boolean storeLoadedValue(K key, int hash, LoadingValueReference<K, V> oldValueReference,
V newValue) {
lock();
try {
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count + 1;
if (newCount > this.threshold) { // ensure capacity
expand();
newCount = this.count + 1;
}
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
//找到
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
ValueReference<K, V> valueReference = e.getValueReference();
V entryValue = valueReference.get();
// replace the old LoadingValueReference if it's live, otherwise
// perform a putIfAbsent
if (oldValueReference == valueReference
|| (entryValue == null && valueReference != UNSET)) {
++modCount;
if (oldValueReference.isActive()) {
RemovalCause cause =
(entryValue == null) ? RemovalCause.COLLECTED : RemovalCause.REPLACED;
enqueueNotification(key, hash, oldValueReference, cause);
newCount--;
}
//LoadingValueReference变成对应引用类型的ValueReference,并进行赋值
setValue(e, key, newValue, now);
//volatile写入
this.count = newCount; // write-volatile
evictEntries();
return true;
}
// the loaded value was already clobbered
valueReference = new WeightedStrongValueReference<K, V>(newValue, 0);
enqueueNotification(key, hash, valueReference, RemovalCause.REPLACED);
return false;
}
}
++modCount;
ReferenceEntry<K, V> newEntry = newEntry(key, hash, first);
setValue(newEntry, key, newValue, now);
table.set(index, newEntry);
this.count = newCount; // write-volatile
evictEntries();
return true;
} finally {
unlock();
postWriteCleanup();
}
}
至此get方法获取,加载数据完成,那么数据是如何过期的呢?继续看
/**
* 在查询的时候刷新
*/
V scheduleRefresh(ReferenceEntry<K, V> entry, K key, int hash, V oldValue, long now,
CacheLoader<? super K, V> loader) {
if (map.refreshes() && (now - entry.getWriteTime() > map.refreshNanos)
&& !entry.getValueReference().isLoading()) {
V newValue = refresh(key, hash, loader, true);
if (newValue != null) {
return newValue;
}
}
return oldValue;
}
/**
* 异步刷新
*/
@Nullable
V refresh(K key, int hash, CacheLoader<? super K, V> loader, boolean checkTime) {
final LoadingValueReference<K, V> loadingValueReference =
insertLoadingValueReference(key, hash, checkTime);
if (loadingValueReference == null) {
return null;
}
ListenableFuture<V> result = loadAsync(key, hash, loadingValueReference, loader);
if (result.isDone()) {
try {
return Uninterruptibles.getUninterruptibly(result);
} catch (Throwable t) {
// don't let refresh exceptions propagate; error was already logged
}
}
return null;
}
/**
* 开启一个线程去做
*/
ListenableFuture<V> loadAsync(final K key, final int hash,
final LoadingValueReference<K, V> loadingValueReference, CacheLoader<? super K, V> loader) {
final ListenableFuture<V> loadingFuture = loadingValueReference.loadFuture(key, loader);
loadingFuture.addListener(
new Runnable() {
@Override
public void run() {
try {
V newValue = getAndRecordStats(key, hash, loadingValueReference, loadingFuture);
} catch (Throwable t) {
logger.log(Level.WARNING, "Exception thrown during refresh", t);
loadingValueReference.setException(t);
}
}
}, directExecutor());
return loadingFuture;
}
核心代码到这里算是读完了,但是感觉还要仔细读读好几遍才行呀,说下回收的机制:
1)基于容量回收:CacheBuilder.maximumSize(long)
2)定时回收:(看源码实在获取的时候会把所有的过期数据清空一边)
expireAfterAccess(long, TimeUnit):缓存项在给定时间内没有被读/写访问,则回收。
expireAfterWrite(long, TimeUnit):缓存项在给定时间内没有被写(创建或覆盖),则回收。
3)基于引用回收:
CacheBuilder.weakKeys():使用弱引用存储键。当键没有其它(强或软)引用时,缓存项可以被垃圾回收。因为垃圾回收仅依赖恒等式(==),使用弱引用键的缓存用==而不是equals比较键。
CacheBuilder.weakValues():使用弱引用存储值。当值没有其它(强或软)引用时,缓存项可以被垃圾回收。因为垃圾回收仅依赖恒等式(==),使用弱引用值的缓存用==而不是equals比较值。
CacheBuilder.softValues():使用软引用存储值。软引用只有在响应内存需要时,才按照全局最近最少使用的顺序回收。考虑到使用软引用的性能影响,我们通常建议使用更有性能预测性的缓存大小限定(见上文,基于容量回收)。使用软引用值的缓存同样用==而不是equals比较值。
4)显式清除:任何时候,你都可以显式地清除缓存项,而不是等到它被回收,具体如下
个别清除:Cache.invalidate(key)
批量清除:Cache.invalidateAll(keys)
清除所有缓存项:Cache.invalidateAll()
虽然感觉还是很弱,还是得撑着头皮总结下呀:
1、guava cache第一获取或者刷新元素的时候并不简单,各种加锁,数据一致性处理,只是减少了mysql业务等的压力
2、如果缓存中已经有数据,这个流程会简单很多
3、一个观念更加清晰:走缓存的数据第一次先查库,set数据到缓存,然后返回
4、guava cache使用segement是为了增加并发能力,否则,整个流程会慢很多
5、如果业务中缓存太多,key太多会使得太多key到一个segment,一定程度应该会慢(竞争锁)
6、segment继承了ReentrantLock
7、segment中的LocalMap,但是只作为基本变量使用,获取外部变量值,LocalCache感觉就是一个大boss
CacheBuilder的3种失效重载模式
1.expireAfterWrite
当 创建 或 写之后的 固定 有效期到达时,数据会被自动从缓存中移除,源码注释如下:
参考文档:
/**指明每个数据实体:当 创建 或 最新一次更新 之后的 固定值的 有效期到达时,数据会被自动从缓存中移除
* Specifies that each entry should be automatically removed from the cache once a fixed duration
* has elapsed after the entry's creation, or the most recent replacement of its value.
*当间隔被设置为0时,maximumSize设置为0,忽略其它容量和权重的设置。这使得测试时 临时性地 禁用缓存且不用改代码。
* <p>When {@code duration} is zero, this method hands off to {@link #maximumSize(long)
* maximumSize}{@code (0)}, ignoring any otherwise-specified maximum size or weight. This can be
* useful in testing, or to disable caching temporarily without a code change.
*过期的数据实体可能会被Cache.size统计到,但不能进行读写,数据过期后会被清除。
* <p>Expired entries may be counted in {@link Cache#size}, but will never be visible to read or
* write operations. Expired entries are cleaned up as part of the routine maintenance described
* in the class javadoc.
*
* @param duration the length of time after an entry is created that it should be automatically
* removed
* @param unit the unit that {@code duration} is expressed in
* @return this {@code CacheBuilder} instance (for chaining)
* @throws IllegalArgumentException if {@code duration} is negative
* @throws IllegalStateException if the time to live or time to idle was already set
*/
public CacheBuilder<K, V> expireAfterWrite(long duration, TimeUnit unit) {
checkState(
expireAfterWriteNanos == UNSET_INT,
"expireAfterWrite was already set to %s ns",
expireAfterWriteNanos);
checkArgument(duration >= 0, "duration cannot be negative: %s %s", duration, unit);
this.expireAfterWriteNanos = unit.toNanos(duration);
return this;
}
2.expireAfterAccess
指明每个数据实体:当 创建 或 写 或 读 之后的 固定值的有效期到达时,数据会被自动从缓存中移除。读写操作都会重置访问时间,但asMap方法不会。源码注释如下:
/**指明每个数据实体:当 创建 或 更新 或 访问 之后的 固定值的有效期到达时,数据会被自动从缓存中移除。读写操作都会重置访问时间,但asMap方法不会。
* Specifies that each entry should be automatically removed from the cache once a fixed duration
* has elapsed after the entry's creation, the most recent replacement of its value, or its last
* access. Access time is reset by all cache read and write operations (including
* {@code Cache.asMap().get(Object)} and {@code Cache.asMap().put(K, V)}), but not by operations
* on the collection-views of {@link Cache#asMap}.
* 后面的同expireAfterWrite
* <p>When {@code duration} is zero, this method hands off to {@link #maximumSize(long)
* maximumSize}{@code (0)}, ignoring any otherwise-specified maximum size or weight. This can be
* useful in testing, or to disable caching temporarily without a code change.
*
* <p>Expired entries may be counted in {@link Cache#size}, but will never be visible to read or
* write operations. Expired entries are cleaned up as part of the routine maintenance described
* in the class javadoc.
*
* @param duration the length of time after an entry is last accessed that it should be
* automatically removed
* @param unit the unit that {@code duration} is expressed in
* @return this {@code CacheBuilder} instance (for chaining)
* @throws IllegalArgumentException if {@code duration} is negative
* @throws IllegalStateException if the time to idle or time to live was already set
*/
public CacheBuilder<K, V> expireAfterAccess(long duration, TimeUnit unit) {
checkState(
expireAfterAccessNanos == UNSET_INT,
"expireAfterAccess was already set to %s ns",
expireAfterAccessNanos);
checkArgument(duration >= 0, "duration cannot be negative: %s %s", duration, unit);
this.expireAfterAccessNanos = unit.toNanos(duration);
return this;
}
3.refreshAfterWrite
指明每个数据实体:当 创建 或 写 之后的 固定值的有效期到达时,且新请求过来时,数据会被自动刷新(注意不是删除是异步刷新,不会阻塞读取,先返回旧值,异步重载到数据返回后复写新值)。源码注释如下:
/**指明每个数据实体:当 创建 或 更新 之后的 固定值的有效期到达时,数据会被自动刷新。刷新方法在LoadingCache接口的refresh()申明,实际最终调用的是CacheLoader的reload()
* Specifies that active entries are eligible for automatic refresh once a fixed duration has
* elapsed after the entry's creation, or the most recent replacement of its value. The semantics
* of refreshes are specified in {@link LoadingCache#refresh}, and are performed by calling
* {@link CacheLoader#reload}.
* 默认reload是同步方法,所以建议用户覆盖reload方法,否则刷新将在无关的读写操作间操作。
* <p>As the default implementation of {@link CacheLoader#reload} is synchronous, it is
* recommended that users of this method override {@link CacheLoader#reload} with an asynchronous
* implementation; otherwise refreshes will be performed during unrelated cache read and write
* operations.
*
* <p>Currently automatic refreshes are performed when the first stale request for an entry
* occurs. The request triggering refresh will make a blocking call to {@link CacheLoader#reload}
* and immediately return the new value if the returned future is complete, and the old value
* otherwise.触发刷新操作的请求会阻塞调用reload方法并且当返回的Future完成时立即返回新值,否则返回旧值。
*
* <p><b>Note:</b> <i>all exceptions thrown during refresh will be logged and then swallowed</i>.
*
* @param duration the length of time after an entry is created that it should be considered
* stale, and thus eligible for refresh
* @param unit the unit that {@code duration} is expressed in
* @return this {@code CacheBuilder} instance (for chaining)
* @throws IllegalArgumentException if {@code duration} is negative
* @throws IllegalStateException if the refresh interval was already set
* @since 11.0
*/
@GwtIncompatible // To be supported (synchronously).
public CacheBuilder<K, V> refreshAfterWrite(long duration, TimeUnit unit) {
checkNotNull(unit);
checkState(refreshNanos == UNSET_INT, "refresh was already set to %s ns", refreshNanos);
checkArgument(duration > 0, "duration must be positive: %s %s", duration, unit);
this.refreshNanos = unit.toNanos(duration);
return this;
}
Guava Cache源码详解 https://www.cnblogs.com/dennyzhangdd/p/8981982.html
缓存框架Guava Cache部分源码分析 https://blog.51cto.com/jincheng/1827153
官方文档 https://github.com/google/guava/wiki/ImmutableCollectionsExplained
Guava LocalCache 缓存介绍及实现源码深入剖析 https://ketao1989.github.io/2014/12/19/Guava-Cache-Guide-And-Implement-Analyse/
深入Guava Cache的refresh和expire刷新机制 https://blog.csdn.net/abc86319253/article/details/53020432
缓存那些事 https://tech.meituan.com/2017/03/17/cache-about.html
Google Guava Cache 全解析 https://www.jianshu.com/p/38bd5f1cf2f2