
概述
本文主要的目的是为了讲述一个SQL如何从XML文件中被解析出来,以及到能够被执行过程中的一些关键步骤。
Mybatis中的SQL
先来看一下Mybatis中的一个简单的SQL是什么样的。
<update id="updateUser" parameterType="com.matrix.matrixweb.benchmark.bean.User">
<!-- 第一个子节点是一个文本 -->
update user
<!-- 第二个子节点是一个标签 -->
<set >
<!-- 第二个子节点第一个子标签,是一个if标签 -->
<if test="name != null" >
<!-- 第二个子节点第二个子标签是一个文本 -->
name = #{name,jdbcType=VARCHAR}
</if>
</set>
<!-- 第三个子节点是一个文本 -->
where id = #{id,jdbcType=BIGINT}
</update>
Mybatis中是如何解析SQL的
在Mybatis中一个SQL是由若干个SqlNode来表示的。
protected MixedSqlNode parseDynamicTags(XNode node) {
// 最终解析到的SqlNode,最后这个列表里面的节点都是一个个嵌套的。
List<SqlNode> contents = new ArrayList<SqlNode>();
// 获取节点的子节点列表
NodeList children = node.getNode().getChildNodes();
// 遍历子节点列表
for (int i = 0; i < children.getLength(); i++) {
// 转成一个XNode
XNode child = node.newXNode(children.item(i));
// 判断是否是文本节点
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
// 获取文本
String data = child.getStringBody("");
// 首先解析成一个TextSqlNode
TextSqlNode textSqlNode = new TextSqlNode(data);
// 是否是动态文本,逻辑是文本中是否存在$,如果存在需要对其进行转换成对应的值。
if (textSqlNode.isDynamic()) {
// 放到结果集中
contents.add(textSqlNode);
// 标识一下这个标签存在动态文本
isDynamic = true;
} else {
// 到这里就是纯文本,可以存在#,最后解析的时候会替换成?,然后值存放在MappingParameter中
contents.add(new StaticTextSqlNode(data));
}
// 到这里就代表这是一个标签,需要使用对应的标签解析器执行动态解析。
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
// 获取节点名
String nodeName = child.getNode().getNodeName();
// 通过节点名获取不同的解析器
NodeHandler handler = nodeHandlerMap.get(nodeName);
// 没有解析到就抛出异常
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
// 调用解析器开始解析
handler.handleNode(child, contents);
// 标记该标签是动态的
isDynamic = true;
}
}
// 最后解析完成返回一个混合标签。
return new MixedSqlNode(contents);
}
这是一个通用方法,主要用来解析文本节点和动态标签节点两种情况,如果是文本节点,直接封装成一个节点放到结果集中,如果是动态标签节点,那么会重新调用这个方法继续解析,直到将所有的子节点解析完成。
文本节点解析比较简单,上面已经把逻辑讲清楚了。
下面我们主要看看不同的标签是如何解析成SQL的。为了解析这些动态节点,mybatis定义了很多NodeHandler专门用来将节点转换成对应的SqlNode。而SqlNode的作用,后面我们在将,这里先把SqlNode如何构建讲清楚。
NodeHandler
private interface NodeHandler {
// 当前的根节点和SqlNode结果集,这个方法的作用就是根据根节点,
// 解析所有的子节点转换成SqlNode。
void handleNode(XNode nodeToHandle, List<SqlNode> targetContents);
}
//每个标签映射不同的处理器
nodeHandlerMap.put("trim", new TrimHandler());
nodeHandlerMap.put("where", new WhereHandler());
nodeHandlerMap.put("set", new SetHandler());
nodeHandlerMap.put("foreach", new ForEachHandler());
nodeHandlerMap.put("if", new IfHandler());
nodeHandlerMap.put("choose", new ChooseHandler());
nodeHandlerMap.put("when", new IfHandler());
nodeHandlerMap.put("otherwise", new OtherwiseHandler());
nodeHandlerMap.put("bind", new BindHandler());
TrimHandler
trim标签主要是用来增加或者去掉一些特定的文本内容
private class TrimHandler implements NodeHandler {
public TrimHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 因为trim标签是一个嵌套标签里面还有文本节点和动态节点,所以需要继续解析。
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
// trim标签里面的内容解析完成之后。
// 前缀
String prefix = nodeToHandle.getStringAttribute("prefix");
// 前缀需要替换的
String prefixOverrides = nodeToHandle.getStringAttribute("prefixOverrides");
// 后缀
String suffix = nodeToHandle.getStringAttribute("suffix");
// 后缀需要替换的
String suffixOverrides = nodeToHandle.getStringAttribute("suffixOverrides");
// 最后将这些属性封装到TrimSqlNode中。后续会继续解析
TrimSqlNode trim = new TrimSqlNode(configuration, mixedSqlNode, prefix, prefixOverrides, suffix, suffixOverrides);
targetContents.add(trim);
}
}
WhereHandler
WhereHandler复用了TrimHandler,只不过是把前缀写成where 然后把and or之类的文本替换。
private class WhereHandler implements NodeHandler {
public WhereHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// WHERE标签是一个嵌套标签,需要继续去解析里面的内容
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
// 将解析到的里面的内容封装到where标签里面。
WhereSqlNode where = new WhereSqlNode(configuration, mixedSqlNode);
targetContents.add(where);
}
}
这里我们仅仅列举了其中的两个用来说明从标签解析成SqlNode的一个过程。
最后我们来总结下:
1、解析标签的过程中一般都是存在文字标签和动态标签而动态标签一般都是内容嵌套的,所以在解析的使用如果解析到动态标签,那么会递归解析。
2、抽象出SqlNode的意义是需要一个结构来描述一个SQL节点的关键信息。后续在解析的时候,我们可以通过这些关键信息来还原出最终的SQL。有个问题就是为什么不一次性就将SQL解析完成呢?mybatis实现的时候是在具体执行的时候才会触发SQL的最终解析。为什么这样呢?主要是因为SQL中的一些标签的属性依赖调用参数,所以先把关键信息解析出来,这样省去了每次需要解析XNode了。所以,每次执行SQL的时候,都需要根据SqlNode的信息再重新组装一遍。
SqlNode
上面已经讲了SqlNode的主要作用是持有一些SQL节点的关键信息,用来后续组装SQL的时候使用。
我把SqlNode归一下类:
IfSqlNode 最简单的具有判断能力的标签,如果表达式是true才会应用标签的内容。
ChooseSqlNode 具有选择能力的标签,if/else实现,它是一个嵌套标签。
ForEachSqlNode 迭代标签。
TrimSqlNode 替换和覆盖逻辑标签
WhereSqlNode 基于trim标签实现的
SetSqlNode 基于trim标签实现的
可以看到上面这几类标签都是基于某种条件,然后组装出对应的SQL文本。
StaticTextSqlNode 纯文本节点
TextSqlNode 带有$符号的节点
MixedSqlNode 一种混合节点,持有上面所列举标签的一个List。通常最后是通过它来解析一个完整的SQl到context里面的。
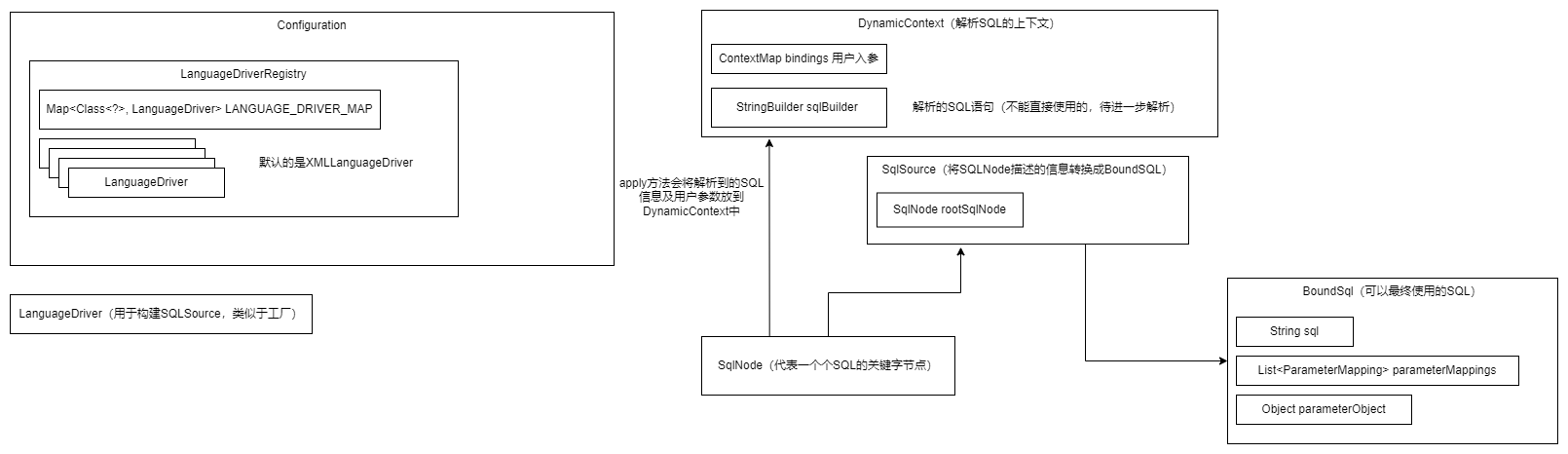
SqlNode组装SQL是在Executor中调用的,通过MappedStatement获取到对应SQL节点的SqlNode。
然后调用apply方法获取一个BoundSql,这个就是最终可以直接执行的Sql了,另外BoundSql中有ParameterMapping,用来描述哪个位置是哪个参数,比如???这种,因为SQL最终组装完成后会把#符号替换成?,替换完成后需要记录一下这个位置的参数是什么,后续ParameterHandler在赋值的时候直到这个位置应该使用哪个参数的值。
SqlSource
SqlSource的主要作用是,通过SqlNode的中的信息将SQL还原出来,返回一个BoundSql。
解析SQl是一个非常复杂的动作,而SqlSource,SqlNode和Context这种模式是非常值得借鉴的。所以这里面可以看到其实SqlSource是一个服务域,用于持有SqlNode的对象,并且对外暴露组装SQL的API。SqlNode是一个实体域,它是服务域的操作对象,Context是属于会话域持有一次操作的上下文信息。
注意,从下面的代码来看mybatis在每次执行SQL的时候还是会有很多配置的解析工作需要做。需要考虑下,里面是不是有部分内容是没有必要每次都需要执行的。
SqlSource分为两种:
1、DynamicSqlSource,当存在动态标签,#符号等需要根据入参来解析SQL时候。
代码如下:
@Override
public BoundSql getBoundSql(Object parameterObject) {
// 初始化一个上下文信息,注意它持有一个入参对象。
DynamicContext context = new DynamicContext(configuration, parameterObject);
// 开始解析SQL。每个SqlNode都需要使用这个Context来记录解析到的SQL片段,最后组成一个完整的。
rootSqlNode.apply(context);
// 到这里已经解析完成了。但是还需要执行最后一步#替换
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
for (Map.Entry<String, Object> entry : context.getBindings().entrySet()) {
boundSql.setAdditionalParameter(entry.getKey(), entry.getValue());
}
return boundSql;
}
public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {
// 参数解析处理器
ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
// 执行替换#操作
GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
String sql = parser.parse(originalSql);
// 返回最终解析到的SQL,注意这里用了StaticSqlSource,它只是存一下SQL,别的什么作用都没有。
return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
}
// 再看一下参数处理器里面的逻辑。这部分很重要,涉及到你传入的值能不能匹配到对应的值
@Override
public String handleToken(String content) {
// 每次遇到#,做两件事,1、解析对应的ParameterMapping,2、将#替换成?
parameterMappings.add(buildParameterMapping(content));
return "?";
}
// 解析对应的ParameterMapping
private ParameterMapping buildParameterMapping(String content) {
// 这里面的解析主要是将property typeHandler和jdbcType之类的参数解析成一个Map返回
Map<String, String> propertiesMap = parseParameterMapping(content);
// 获取参数名,注意是XML配置文件中的
String property = propertiesMap.get("property");
Class<?> propertyType;
// 判断附加对象里面,入参里面是否有对应的参数,这个用法目前不知道,先忽略
if (metaParameters.hasGetter(property)) { // issue #448 get type from additional params
// 如果有,就获取参数类型
propertyType = metaParameters.getGetterType(property);
} else if (typeHandlerRegistry.hasTypeHandler(parameterType)) {
// 如果没有。那么看看是否有typeHandler能够处理这种类型,如果有也可以。
propertyType = parameterType;
} else if (JdbcType.CURSOR.name().equals(propertiesMap.get("jdbcType"))) {
propertyType = java.sql.ResultSet.class;
} else if (property == null || Map.class.isAssignableFrom(parameterType)) {
propertyType = Object.class;
} else {
// 通过反射,来获取参数信息
MetaClass metaClass = MetaClass.forClass(parameterType, configuration.getReflectorFactory());
// 判断是否有对应的getter方法
if (metaClass.hasGetter(property)) {
// 如果有,就使用这个类型
propertyType = metaClass.getGetterType(property);
} else {
propertyType = Object.class;
}
}
// 构建一个ParameterMapping
ParameterMapping.Builder builder = new ParameterMapping.Builder(configuration, property, propertyType);
Class<?> javaType = propertyType;
String typeHandlerAlias = null;
for (Map.Entry<String, String> entry : propertiesMap.entrySet()) {
String name = entry.getKey();
String value = entry.getValue();
if ("javaType".equals(name)) {
javaType = resolveClass(value);
builder.javaType(javaType);
} else if ("jdbcType".equals(name)) {
builder.jdbcType(resolveJdbcType(value));
} else if ("mode".equals(name)) {
builder.mode(resolveParameterMode(value));
} else if ("numericScale".equals(name)) {
builder.numericScale(Integer.valueOf(value));
} else if ("resultMap".equals(name)) {
builder.resultMapId(value);
} else if ("typeHandler".equals(name)) {
typeHandlerAlias = value;
} else if ("jdbcTypeName".equals(name)) {
builder.jdbcTypeName(value);
} else if ("property".equals(name)) {
// Do Nothing
} else if ("expression".equals(name)) {
throw new BuilderException("Expression based parameters are not supported yet");
} else {
throw new BuilderException("An invalid property '" + name + "' was found in mapping #{" + content + "}. Valid properties are " + parameterProperties);
}
}
if (typeHandlerAlias != null) {
builder.typeHandler(resolveTypeHandler(javaType, typeHandlerAlias));
}
return builder.build();
}
最后解析到的ParameterMapping很重要,后面ParameterHandler的时候会用它来赋值。
分页查询逻辑就是在这个ParameterMapping的List里面添加limit和offset对应的参数实现的。
总结
无论是StaticSqlSource、DynamicSqlSource还是RawSqlSource,最终都会统一生成BoundSql对象,其中封装了完整的SQL语句(可能还包含“?”占位符)、参数映射关系(parameterMappings集合)以及用户传入的参数(additionalParameters集合)。另外,DynamicSqlSource负责处理动态SQL语句,RawSqlSource负责处理静态SQL语句。除此之外,两者解析SQL语句的时机也不一样,前者的解析时机是在实际执行SQL语句之前,而后者则是在Mybatis初始化时完成SQL语句的解析。
一些关于架构的思考
我们上面讲到解析SQl是一个非常复杂的动作,而SqlSource,SqlNode和Context这种模式是非常值得借鉴的。这里面可以看到其实SqlSource是一个服务域,用于持有SqlNode的对象,并且对外暴露组装SQL的API。SqlNode是一个实体域,它是服务域的操作对象,Context是属于会话域持有一次操作的上下文信息。那么为什么要这样设计呢?这样设计的好处是什么?
这里面讲到了服务域、会话域、实体域这三个概念,这三部分作为一个框架或者一个组件的设计原则,就是我们通常是将实体域作为框架或者组件的核心功能实现,其内部可能非常复杂涉及到的其他模块也非常多,它们都是用来支撑实体域的功能的。而会话域指的是框架的一次调用的信息,强调的是执行。而服务域可以看作是整个框架的门面,它提供了这个框架对外的所有服务接口,同时负责管理会话域和实体域的生命周期。
设计框架的一种范式:
1、配置解析:这里的配置解析是指通过约定好的配置文件,解析称为框架内部驱动运行的数据接口,可以是原始的,也可以是经过加工的。
2、驱动执行:框架各个模块之间的流转,需要用到上面的数据结构。