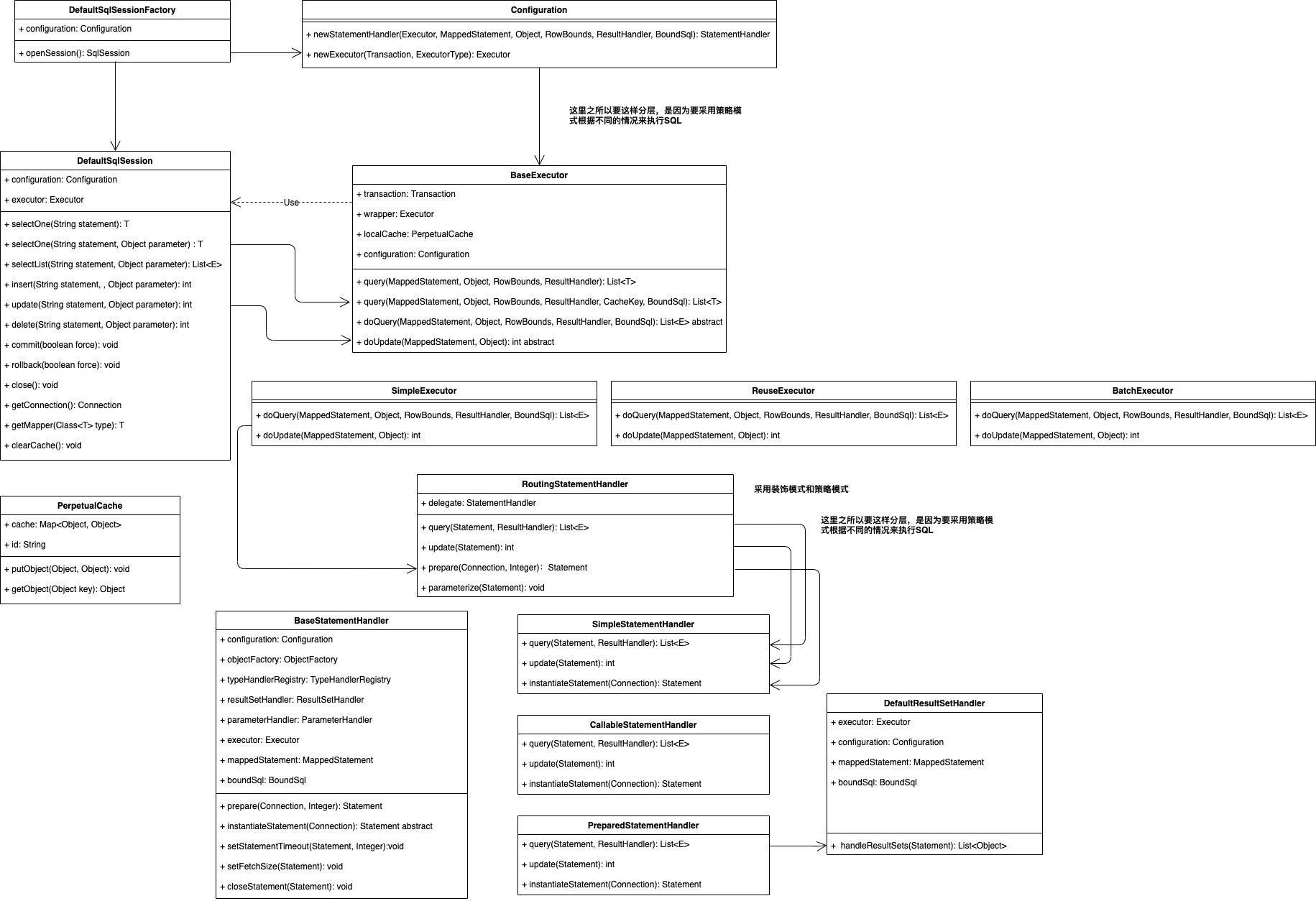
1、概述
此阶段属于框架的用户执行调用。bingding引擎的主要作用是在封装JDBC的Statement操作数据库,且对查询阶段的返回结果进行处理。部分概述引用了相关的资料。
binding引擎由以下几部分组成:
(1)、SqlSession:用户操作数据库的门面类,主要用于对用户提供相应的数据库操作。
(2)、Executor:执行操作数据库的具体操作。
(3)、StatementHandler:用于根据不同的场景下执行真正的数据库操作。
1.1、StatementHandler
StatementHandler接口是Mybatis的核心接口之一,它完成了Mybatis中最核心的工作,也是Executor接口实现的基础。
Statement接口总的功能很多,例如创建Statement对象,为SQL语句绑定实参,执行select、insert、update、delete等多种类型的SQL语句,批量执行SQL语句,将结果集映射成结果对象。
接口定义如下:
public interface StatementHandler {
// 通过Connection创建Statement对象
Statement prepare(Connection connection, Integer transactionTimeout)
throws SQLException;
// 给Statement对象设置对应的参数
void parameterize(Statement statement)
throws SQLException;
// 执行批量操作
void batch(Statement statement)
throws SQLException;
// 执行更新操作,更新操作中包括insert、update、delete
int update(Statement statement)
throws SQLException;
// 执行查询操作,查询操作中list查询和单个查询是放到一起来做的
<E> List<E> query(Statement statement, ResultHandler resultHandler)
throws SQLException;
<E> Cursor<E> queryCursor(Statement statement)
throws SQLException;
BoundSql getBoundSql();
ParameterHandler getParameterHandler();
}
Statement的实现类如下:
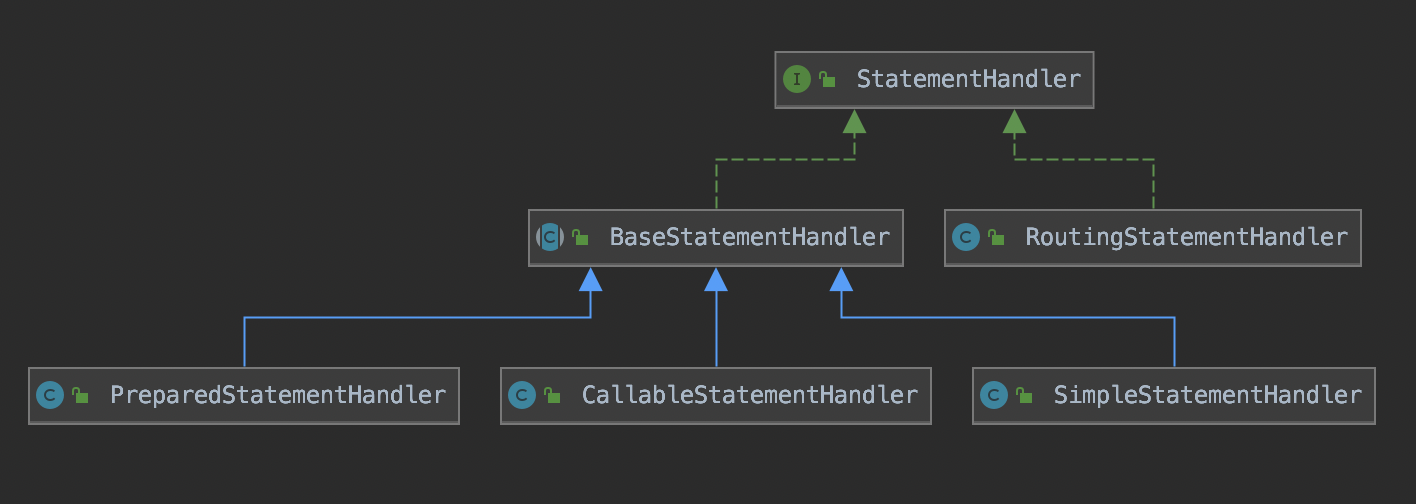
1.1.1、RoutingStatementHandler
对于RoutingStatementHandler在整个StatementHandler接口层次中其实起到了两个作用一是采用了装饰模式,将其他的StatementHandler子类进行了装饰,对外提供服务,二是在创建StatementHandler实例时使用了策略模式来完成不同的场景下的支持。
RoutingStatementHandler会根据MappedStatement中指定的statementType字段,创建对应的StatementHandler接口的实现。具体代码如下:
// 封装真正用于操作数据库的StatementHandler对象
private final StatementHandler delegate;
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
1.1.2、BaseStatementHandler
BaseStatementHandler是一个实现了StatementHandler接口的抽象类,它只提供了一些创建Statement和参数绑定相关方法,并没有实现操作数据库的方法。BaseStatementHandler中核心字段的含义如下:
// 持有Configuration的引用
protected final Configuration configuration;
protected final ObjectFactory objectFactory;
// 类型转换器
protected final TypeHandlerRegistry typeHandlerRegistry;
// 结果转换器
protected final ResultSetHandler resultSetHandler;
protected final ParameterHandler parameterHandler;
protected final Executor executor;
protected final MappedStatement mappedStatement;
protected final RowBounds rowBounds;
// SQL语句
protected BoundSql boundSql;
protected BaseStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
this.configuration = mappedStatement.getConfiguration();
this.executor = executor;
this.mappedStatement = mappedStatement;
this.rowBounds = rowBounds;
this.typeHandlerRegistry = configuration.getTypeHandlerRegistry();
this.objectFactory = configuration.getObjectFactory();
if (boundSql == null) { // issue #435, get the key before calculating the statement
// 初始化SQL语句的主键
generateKeys(parameterObject);
boundSql = mappedStatement.getBoundSql(parameterObject);
}
this.boundSql = boundSql;
this.parameterHandler = configuration.newParameterHandler(mappedStatement, parameterObject, boundSql);
this.resultSetHandler = configuration.newResultSetHandler(executor, mappedStatement, rowBounds, parameterHandler, resultHandler, boundSql);
}
BaseStatementHandler实现了StatementHandler接口中的prepare()方法,该方法首先调用instantiateStatement()抽象方法初始化java.sql.Statement对象,然后为其配置超时时间以及fetchSize等设置。
BaseStatementHandler依赖了两个重要的组件,它们分别是ParameterHandler和ResultSetHandler。其中ResultSetHandler接口以及相关实现后面详细说明。
ParameterHandler接口中只定义了一个setParameters()方法,该方法主要负责调用PreparedStatement.set*()方法为SQL语句绑定实参。Mybatis只为ParameterHandler接口提供了唯一一个实现类,DefaultParameterHandler。核心字段如下:
// 管理Mybatis中的类型转换器
private final TypeHandlerRegistry typeHandlerRegistry;
// 记录SQL节点对应的配置信息
private final MappedStatement mappedStatement;
// 传入的实参对象
private final Object parameterObject;
private final BoundSql boundSql;
private final Configuration configuration;
public DefaultParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
this.mappedStatement = mappedStatement;
this.configuration = mappedStatement.getConfiguration();
this.typeHandlerRegistry = mappedStatement.getConfiguration().getTypeHandlerRegistry();
this.parameterObject = parameterObject;
this.boundSql = boundSql;
}
setParameters()方法中会遍历BoundSql.parameterMapping集合中记录的ParameterMapping对象,并根据其中记录的参数名称查找对应的实参,然后与SQL语句绑定。代码如下:
@Override
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
try {
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
} catch (SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}
绑定实参后就可以调用Statement对象对应的execute()方法,将SQL语句交给数据库执行。
1.1.3、SimpleStatementHandler
SimpleStatementHandler继承了BaseStatementHandler抽象类。它底层使用了java.sql.Statement对象来完成对数据库的相关操作,所以SQL语句中不能存在占位符,相应的,SimpleStatementHandler.parameterize()方法是空实现。
SimpleStatementHandler.instantiateStatement()方法直接通过JDBC Connection创建Statement对象,代码如下:
@Override
protected Statement instantiateStatement(Connection connection) throws SQLException {
if (mappedStatement.getResultSetType() != null) {
// 设置结果集是否可以滚动及其游标是否可以上下移动,设置结果集是否可更新。
return connection.createStatement(mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
} else {
return connection.createStatement();
}
}
SimpleStatementHandler.query()方法完成了数据库的查询操作,并通过ResultSetHandler将结果集映射成结果对象。
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 获取SQL语句
String sql = boundSql.getSql();
// 指定SQL语句
statement.execute(sql);
// 处理返回结果
return resultSetHandler.<E>handleResultSets(statement);
}
SimpleStatementHandler.update()方法负责执行insert、update或delete等类型的SQL语句,并且会根据配置的KeyGenerator获取数据库生成的主键,代码如下:
@Override
public int update(Statement statement) throws SQLException {
// 获取SQL语句
String sql = boundSql.getSql();
// 获取用户传入的实参
Object parameterObject = boundSql.getParameterObject();
// 获取配置的KeyGenerator对象
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
int rows;
if (keyGenerator instanceof Jdbc3KeyGenerator) {
// 执行SQL语句
statement.execute(sql, Statement.RETURN_GENERATED_KEYS);
// 获取受影响的行数
rows = statement.getUpdateCount();
// 将数据库生成的主键添加到parameterObject中
keyGenerator.processAfter(executor, mappedStatement, statement, parameterObject);
} else if (keyGenerator instanceof SelectKeyGenerator) {
statement.execute(sql);
rows = statement.getUpdateCount();
keyGenerator.processAfter(executor, mappedStatement, statement, parameterObject);
} else {
statement.execute(sql);
rows = statement.getUpdateCount();
}
return rows;
}
1.1.4、PreparedStatementHandler
PreparedStatementHandler底层依赖于java.sql.PreparedStatement对象来完成数据库的相关操作。在PreparedStatementHandler.parameterize()方法中,会调用ParameterHandler.setParameters()方法来完成SQL语句的参数绑定。代码如下:
@Override
public void parameterize(Statement statement) throws SQLException {
parameterHandler.setParameters((PreparedStatement) statement);
}
PreparedStatementHandler.instantiateStatement()方法直接调用了JDBC Connection的prepareStatement方法创建PreparedStatement对象。代码如下:
@Override
protected Statement instantiateStatement(Connection connection) throws SQLException {
// 获取SQL语句
String sql = boundSql.getSql();
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
// 返回数据库生成的主键
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
// 在insert语句执行完成之后,会将keyColumnNames指定的列返回
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() != null) {
// 设置结果集是否可以滚动以及游标是否可以上下移动,设置结果集是否可更新
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
} else {
// 创建普通的PrepareStatement对象
return connection.prepareStatement(sql);
}
}
1.1.5、CallableStatementHandler
CallableStatementHandler底层依赖于java.sql.CallableStatemen调用指定的存储过程。
1.2、Executor
Executor是Mybatis的核心接口之一,其中定义了数据库操作的基本方法。接口代码如下:
public interface Executor {
ResultHandler NO_RESULT_HANDLER = null;
// 执行update、insert、delete三种类型的SQL语句
int update(MappedStatement ms, Object parameter) throws SQLException;
// 执行select类型的SQL语句,返回值分为结果对象列表或游标对象
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey cacheKey, BoundSql boundSql) throws SQLException;
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException;
<E> Cursor<E> queryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds) throws SQLException;
// 批量执行SQL语句
List<BatchResult> flushStatements() throws SQLException;
// 提交事务
void commit(boolean required) throws SQLException;
// 回滚事务
void rollback(boolean required) throws SQLException;
// 创建缓存中用到的CacheKey对象
CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql);
// 根据CacheKey对象查找缓存
boolean isCached(MappedStatement ms, CacheKey key);
// 清空一级缓存
void clearLocalCache();
// 延迟加载一级缓存中的数据
void deferLoad(MappedStatement ms, MetaObject resultObject, String property, CacheKey key, Class<?> targetType);
// 获取事务对象
Transaction getTransaction();
// 关闭Executor对象
void close(boolean forceRollback);
// Executor对象是否已经关闭
boolean isClosed();
void setExecutorWrapper(Executor executor);
}
Executor接口结构如下:
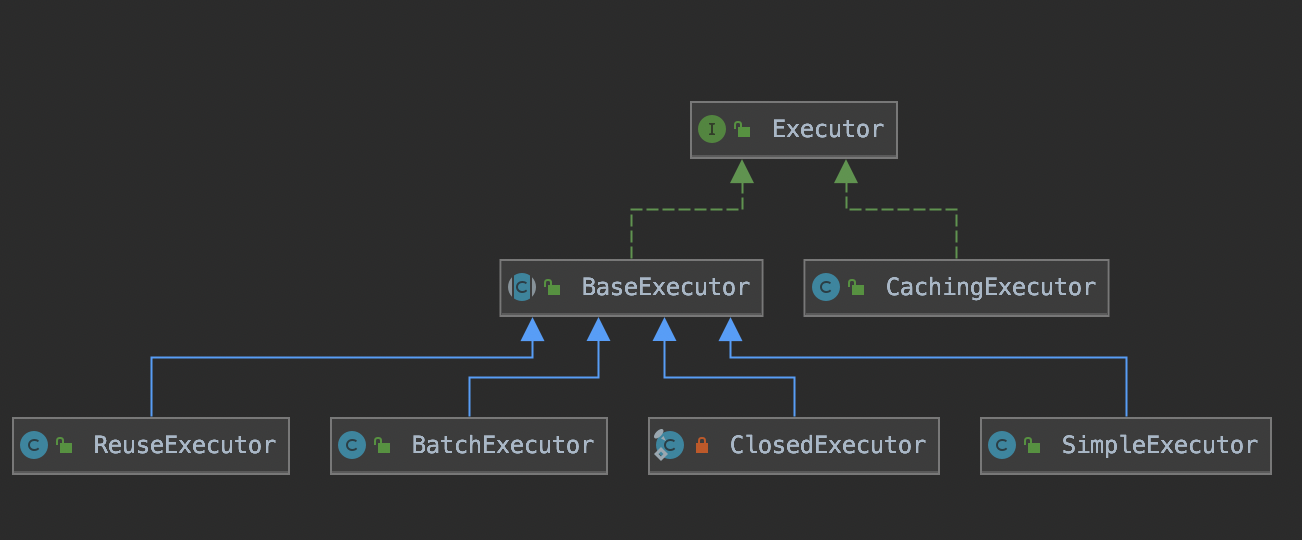
Executor的接口实现中同样也用到了装饰模式、模版模式和策略模式。Executor的实例的创建是在Configuration中实现的,代码如下:
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
// 根据ExecutorType来创建不同的Executor的实现类对象
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
// 如果开启了二级缓存,那么就使用CachingExecutor对象
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
// 实现plugin
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
1.2.1、BaseExecutor
BaseExecutor是一个实现了Executor接口的抽象类,它实现了Executor接口的大部分方法,其中就使用了模版方法模式。BaseExecutor中主要提供了缓存管理和事务管理的基本功能,继承BaseExecutor的子类只要实现了四个基本方法来完成数据库的相关操作即可,这四个方法分别是doUpdate()、doQuery()、doQueryCursor()和doFlushStatement()方法,其余的功能在BaseExecutor中实现。
BaseExecutor中各个字段的含义如下:
// Transaction对象,实现事务的提交、回滚和关闭操作
protected Transaction transaction;
// 封装的Executor对象
protected Executor wrapper;
// 延迟加载队列
protected ConcurrentLinkedQueue<DeferredLoad> deferredLoads;
// 一级缓存,用于缓存该Executor对象的查询结果集映射得到的结果对象
protected PerpetualCache localCache;
// 一级缓存,用于缓存输出类型的参数
protected PerpetualCache localOutputParameterCache;
// Configuration引用
protected Configuration configuration;
// 用来记录嵌套查询的层数
protected int queryStack;
// Executor是否已经被关闭
private boolean closed;
1.2.2、BaseExecutor中关于一级缓存简介
在常见的应用系统中,数据库是比较珍贵的资源,很容易成为整个系统的瓶颈。在设计和维护系统时,会进行多方面的权衡,并且利用多种优化手段,减少对数据库的直接访问。使用缓存是一种比较有效的优化手段,使用缓存可以减少应用系统与数据库的网络交互、减少数据库访问次数、降低数据库的负担、降低重复创建和销毁对象等一系列的开销,从而提供了整个系统的性能。从另一方面来看,当数据库意外宕机时,缓存中保存的数据可以继续支持应用程序中的部分展示功能,提高系统的可用性。
Mybatis作为ORM框架,也提供了缓存功能,其缓存设计为两层结构,分别为一级缓存和二级缓存。二级缓存使用了CachingExecutor来实现。
一级缓存是会话级别的缓存,在Mybatis中每创建一个SqlSession对象,就表示开启一次数据库会话。在一次会话中,应用程序可能会在短时间内,例如一个事务内,反复执行完全相同的查询语句,如果不对数据进行缓存,那么每一次查询都会执行一次数据库查询操作,而多次完全相同的、时间间隔较短的查询语句得到的结果集极有可能完全相同,这也就造成了数据库资源的浪费。
Mybatis中的SqlSession是通过Executor对象完成数据库操作的,为了避免上述问题,在Executor对象中会建立一个简单的缓存,它会将每次的查询结果缓存起来。在执行查询操作时,会先查询一级缓存,如果其中存在完全一样的查询语句,则直接从一级缓存中取出相应的结果对象并返回给用户,这样不需要再访问数据库了,从而减小了数据库的压力。
一级缓存的生命周期与SqlSession相同,其实也就与SqlSession中封装的Executor对象的生命周期相同。当调用Executor对象的close方法时,该Executor对象对应的一级缓存就变得不可用。一级缓存默认是开启的,一般情况下,不需要用户进行特殊的配置。如果存在特殊需求则要考虑使用插件功能。
1.2.3、一级缓存的管理
执行select语句查询数据库是最常用的功能,BaseExecutor.query()方法实现该功能的思路如下:
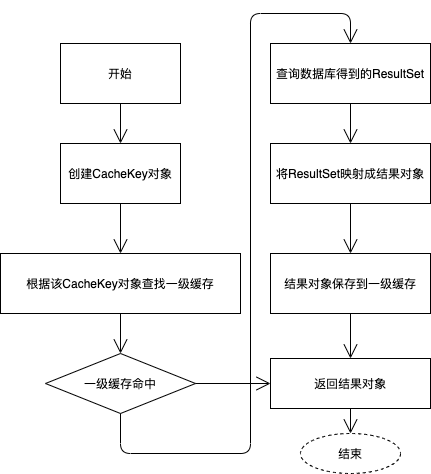
query方法代码如下:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
// 创建CacheKey对象
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
// 调用query方法继续处理
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
createCacheKey方法如下:
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 创建CacheKey对象
CacheKey cacheKey = new CacheKey();
// 将MappedStatement对象的ID添加到CacheKey对象中
cacheKey.update(ms.getId());
// 将offset添加到CacheKey对象中
cacheKey.update(rowBounds.getOffset());
// 将limit添加到CacheKey对象中
cacheKey.update(rowBounds.getLimit());
// 将SQL语句添加到CacheKey对象中
cacheKey.update(boundSql.getSql());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
// 获取用户传入的实参,并添加到CacheKey对象中
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
// 将实参添加到CacheKey对象中
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}
query方法如下:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 查询一级缓存
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 缓存未命中后执行真正的数据库操作
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
这是缓存的第一种功能,也就是缓存结果查询得到的结果对象。除此之外,一级缓存还有第二个功能:如果一级缓存中缓存了嵌套查询的结果对象,则可以从一级缓存中直接加载该结果对象;如果一级缓存中记录的嵌套查询的结果对象并为完全加载,则可以通过DeferredLoad实现类类似延迟加载的功能。
CacheKey对象代码如下:
// 参与计算hashcode,默认值是37
private final int multiplier;
// CacheKey对象的hashcode,初始值为17
private int hashcode;
// 校验和
private long checksum;
// updateList集合的个数
private int count;
// 8/21/2017 - Sonarlint flags this as needing to be marked transient. While true if content is not serializable, this is not always true and thus should not be marked transient.
// 由该集合中的所有对象共同决定两个CacheKey是否相同
private List<Object> updateList;
BaseExecutor.update()方法会根据flushCache属性和localScope配置决定是否清空一级缓存。该方法负责执行insert、update、delete三类SQL语句,它是调用doUpdate模版方法实现的。在调用doUpdate方法之前会清空缓存,因为在执行SQL语句之后,数据库中的数据已经更新了。
1.2.4、事务相关操作
在BaseExecutor实现中,可以缓存多条SQL语句,等待合适的时机将缓存的多条SQL语句一并发送到数据库中执行。Executor.flushStatement()方法主要是针对批处理多条SQL语句的,它会调用doFlushStatements()这个基本方法处理Executor中缓存的多条SQL语句。在BaseExecutor.commit()、rollback()等方法中都会首先调用flushStatements()方法,然后再执行相关事务操作。
1.2.5、SimpleExecutor
SimpleExecutor继承了BaseExecutor抽象类,它是最简单的Executor接口实现。
SimpleExecutor.doQuery()方法如下:
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 创建StatementHandler对象,实际返回的是RoutingStatementHandler对象
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 完成Statement的创建和初始化
stmt = prepareStatement(handler, ms.getStatementLog());
// 调用StatementHandler的query方法,执行SQL语句,并通过ResultSetHandler完成结果集映射
return handler.<E>query(stmt, resultHandler);
} finally {
// 关闭Statement对象
closeStatement(stmt);
}
}
1.2.6、ReuseExecutor
在传统的JDBC缓存中,重用Statement对象是常用的一种优化手段,该优化手段可以减少SQL预编译的开销以及创建和销毁Statement对象的开销,从而提高性能。
ReuseExecutor提供了Statement重用的功能,ReuseExecutor中通过statementMap字段HashMap<String, Statement>类型,缓存使用过的Statement对象,key是SQL语句,value是SQL对应的Statement对象。
ReuseExecutor.doQuery()、doQueryCursor()、doUpdate()方法的实现与SimpleExecutor中对应的实现一样,区别在于其中调用的prepareStatement()方法,SimpleExecutor()方法,SimpleExecutor每次都会通过JDBC Connection创建新的Statement对象,而ReuseExecutor则会先尝试重用StatementMap中缓存的Statement对象。
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
BoundSql boundSql = handler.getBoundSql();
String sql = boundSql.getSql(); // 获取SQL语句
if (hasStatementFor(sql)) { // 检测是否缓存了相同模式的SQL语句所对应的Statement对象
stmt = getStatement(sql); // 获取Statement集合中缓存的Statement对象
applyTransactionTimeout(stmt); // 修改超时时间
} else {
Connection connection = getConnection(statementLog); // 获取数据库连接
// 创建新的Statement对象,并缓存到statementMap集合中
stmt = handler.prepare(connection, transaction.getTimeout());
putStatement(sql, stmt);
}
handler.parameterize(stmt); // 处理占位符
return stmt;
}
当事务提交或回滚、连接关闭时,都需要关闭这些缓存的Statement对象,在BaseExecutor.commit()、rollback()和close()方法时提到,其中都会调用doFlushStatement()方法,所以在该方法中实现关闭Statement对象的逻辑非常合适,具体实现如下:
@Override
public List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException {
for (Statement stmt : statementMap.values()) {
closeStatement(stmt); // 遍历statementMap集合并关闭Statement对象
}
statementMap.clear(); // 清空statementMap缓存
return Collections.emptyList(); // 返回空集合
}
ReuseExecutor.queryCursor()方法的使用,每个Statement对象只能对应一个结果集,当多次调用queryCursor()方法执行同一SQL语句时,会复用同一个Statement对象,只有最后一个ReuseSet是可用的。而queryCursor()方法返回的是Cursor对象,在用户迭代Cursor对象时,才会真正遍历结果集对象并进行映射操作,这就可能导致前面创建的Cursor对象中封装的结果集关闭。
1.2.7、BatchExecutor
应用系统在执行一条SQL语句时,会将SQL语句以及相关参数通过网络发送到数据库系统。对于频繁操作数据库的应用系统来说,如果执行一条SQL语句就向数据库发送一次请求,很多时间会浪费在网络通信上。使用批处理的优化方式可以在客户端缓存多条SQL语句,并在合适的时机将多条SQL语句打包发送给数据库执行,从而减少网络方面的开销,提升系统的性能。
不过有一点需要注意,在批量执行多条SQL语句时,每次向数据库发送的SQL语句条数是有上限的,如果超过这个上限,数据库会拒绝执行这些SQL语句并抛出异常,所以批量发送SQL的时机很重要。
BatchExecutor实现了批处理多条SQL语句的功能,其中核心字段的含义如下,
// 缓存多个Statement对象,其中每个Statement对象中缓存了多条SQL语句
private final List<Statement> statementList = new ArrayList<Statement>();
// 记录批处理结果,BatchResult中通过updateCounts字段执行批处理结果。
private final List<BatchResult> batchResultList = new ArrayList<BatchResult>();
// 记录当前的SQL语句
private String currentSql;
// 记录当前执行的MappedStatement对象
private MappedStatement currentStatement;
JDBC中的批处理只支持insert、update、delete等类型的SQL语句,不支持select类型的SQL语句,所以只会针对BatchExecutor.doUpdate()方法。
BatchExecutor.doUpdate()方法在添加一条SQL语句时,首先会将currentSql字段记录的SQL语句以及currentStatement字段记录的MappedStatement对象与当前添加的SQL语句以及MappedStatement对象进行比较,如果相同则添加到同一个Statement对象中执行,如果不同则创建新的Statement对象并将其缓存到statementList集合中等待执行,doUpdate()方法的实现如下:
@Override
public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException {
// 获取配置对象
final Configuration configuration = ms.getConfiguration();
// 创建StatementHandler对象
final StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject, RowBounds.DEFAULT, null, null);
final BoundSql boundSql = handler.getBoundSql();
// 获取SQL语句
final String sql = boundSql.getSql();
final Statement stmt;
// 如果本次SQL与上次的SQL模式相同,并且MappedStatement对象相同
if (sql.equals(currentSql) && ms.equals(currentStatement)) {
// 获取StatementList集合中最后一个Statement对象
int last = statementList.size() - 1;
stmt = statementList.get(last);
applyTransactionTimeout(stmt);
// 绑定实参,处理?占位符
handler.parameterize(stmt);//fix Issues 322
// 查找对应的BatchResult对象
BatchResult batchResult = batchResultList.get(last);
batchResult.addParameterObject(parameterObject);
} else {
Connection connection = getConnection(ms.getStatementLog());
// 创建新的Statement对象
stmt = handler.prepare(connection, transaction.getTimeout());
// 绑定实参,处理?占位符
handler.parameterize(stmt); //fix Issues 322
// 更新currentSql和currentStatement
currentSql = sql;
currentStatement = ms;
// 将新创建的Statement对象添加到statementList集合中
statementList.add(stmt);
// 添加新的BatchResult对象
batchResultList.add(new BatchResult(ms, sql, parameterObject));
}
// handler.parameterize(stmt);
// 底层通过调用Statement.addBatch()方法添加SQL语句
handler.batch(stmt);
return BATCH_UPDATE_RETURN_VALUE;
}
Statement中可以添加不同模式的SQL,但是每添加一个模式的SQL语句都会触发一次编译操作。PreparedStatement中只能添加同一模式的SQL语句,只会触发一次编译操作,但是可以通过绑定多组不同的实参实现批处理。
doFlushStatements()方法:
@Override
public List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException {
try {
List<BatchResult> results = new ArrayList<BatchResult>();
if (isRollback) {
return Collections.emptyList();
}
for (int i = 0, n = statementList.size(); i < n; i++) {
Statement stmt = statementList.get(i);
applyTransactionTimeout(stmt);
BatchResult batchResult = batchResultList.get(i);
try {
batchResult.setUpdateCounts(stmt.executeBatch());
MappedStatement ms = batchResult.getMappedStatement();
List<Object> parameterObjects = batchResult.getParameterObjects();
KeyGenerator keyGenerator = ms.getKeyGenerator();
if (Jdbc3KeyGenerator.class.equals(keyGenerator.getClass())) {
Jdbc3KeyGenerator jdbc3KeyGenerator = (Jdbc3KeyGenerator) keyGenerator;
jdbc3KeyGenerator.processBatch(ms, stmt, parameterObjects);
} else if (!NoKeyGenerator.class.equals(keyGenerator.getClass())) { //issue #141
for (Object parameter : parameterObjects) {
keyGenerator.processAfter(this, ms, stmt, parameter);
}
}
// Close statement to close cursor #1109
closeStatement(stmt);
} catch (BatchUpdateException e) {
StringBuilder message = new StringBuilder();
message.append(batchResult.getMappedStatement().getId())
.append(" (batch index #")
.append(i + 1)
.append(")")
.append(" failed.");
if (i > 0) {
message.append(" ")
.append(i)
.append(" prior sub executor(s) completed successfully, but will be rolled back.");
}
throw new BatchExecutorException(message.toString(), e, results, batchResult);
}
results.add(batchResult);
}
return results;
} finally {
for (Statement stmt : statementList) {
closeStatement(stmt);
}
currentSql = null;
statementList.clear();
batchResultList.clear();
}
}
1.2.8、CachingExecutor
CachingExecutor是一个Executor接口的装饰器,它为Executor对象增加了二级缓存的相关功能。
二级缓存简介:
Mybatis提供的二级缓存是应用级别的缓存,它的生命周期与应用程序的生命周期相同。与二级缓存相关的配置有三个。
(1)、首先是mybatis-config.xml配置文件中的cacheEnabled配置,它是二级缓存的总开关,只有当该配置为true时,后面两项才有效果,cacheEnabled的默认值为true。具体配置如下:
<settings>
<setting name="useGeneratedKeys" value="true"/>
<setting name="mapUnderscoreToCamelCase" value="false"/>
<setting name="logImpl" value="LOG4J"/>
<!-- 开启二级缓存 -->
<setting name="cacheEnabled" value="true"/>
</settings>
(2)、映射配置文件中可以配置
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
(3)、在select节点中的useCache属性,默认值是true
测试用例:
开启二级缓存后
Reader reader = Resources.getResourceAsReader("mybatis-config.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader);
SqlSession sqlSession1 = factory.openSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
User user1 = userMapper1.getUserById(1);
List<User> users = userMapper1.listAllUser();
sqlSession1.close();
UserMapper userMapper2 = sqlSession1.getMapper(UserMapper.class);
userMapper2.getUserById(1);
结果如下:
[19:44:50:948] [DEBUG] - org.apache.ibatis.transaction.jdbc.JdbcTransaction.setDesiredAutoCommit(JdbcTransaction.java:101) - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@5ccddd20]
[19:44:50:998] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - ==> Preparing: SELECT id, name, password, phone, nick_name, create_time FROM user WHERE id = ?
[19:44:51:038] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - ==> Parameters: 1(Integer)
[19:44:51:110] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - <== Total: 1
User(id=1, name=mowenti, password=123456, phone=1111111, nick_name=mingming, create_time=Mon Mar 23 00:00:00 CST 2020)
[19:44:51:112] [DEBUG] - org.apache.ibatis.cache.decorators.LoggingCache.getObject(LoggingCache.java:62) - Cache Hit Ratio [com.matrix.dao.UserMapper]: 0.0
[19:44:51:112] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - ==> Preparing: SELECT id, name, password, phone, nick_name, create_time FROM user
[19:44:51:112] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - ==> Parameters:
[19:44:51:163] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - <== Total: 4
[User(id=1, name=mowenti, password=123456, phone=1111111, nick_name=mingming, create_time=Mon Mar 23 00:00:00 CST 2020), User(id=2, name=liuwenju, password=123456, phone=123456, nick_name=wenwen, create_time=Mon Mar 23 00:00:00 CST 2020), User(id=3, name=liudehua, password=123456, phone=123456, nick_name=liudehua, create_time=Tue Mar 24 00:00:00 CST 2020), User(id=4, name=jack, password=111, phone=111, nick_name=jack, create_time=Fri Jan 02 00:00:00 CST 1970)]
[19:44:51:164] [DEBUG] - org.apache.ibatis.transaction.jdbc.JdbcTransaction.resetAutoCommit(JdbcTransaction.java:123) - Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@5ccddd20]
[19:44:51:210] [DEBUG] - org.apache.ibatis.transaction.jdbc.JdbcTransaction.close(JdbcTransaction.java:91) - Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@5ccddd20]
// 最后一次的查询并没有执行SQL语句,而是从缓存中换取数据。
[19:44:51:214] [DEBUG] - org.apache.ibatis.cache.decorators.LoggingCache.getObject(LoggingCache.java:62) - Cache Hit Ratio [com.matrix.dao.UserMapper]: 0.3333333333333333
尝试关闭二级缓存后结果如下:
[19:47:36:855] [DEBUG] - org.apache.ibatis.logging.LogFactory.setImplementation(LogFactory.java:135) - Logging initialized using 'class org.apache.ibatis.logging.log4j.Log4jImpl' adapter.
[19:47:36:952] [DEBUG] - org.apache.ibatis.logging.LogFactory.setImplementation(LogFactory.java:135) - Logging initialized using 'class org.apache.ibatis.logging.log4j.Log4jImpl' adapter.
[19:47:37:124] [DEBUG] - org.apache.ibatis.transaction.jdbc.JdbcTransaction.openConnection(JdbcTransaction.java:137) - Opening JDBC Connection
Sun Apr 05 19:47:37 CST 2020 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
[19:47:38:410] [DEBUG] - org.apache.ibatis.transaction.jdbc.JdbcTransaction.setDesiredAutoCommit(JdbcTransaction.java:101) - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@56528192]
[19:47:38:460] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - ==> Preparing: SELECT id, name, password, phone, nick_name, create_time FROM user WHERE id = ?
[19:47:38:491] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - ==> Parameters: 1(Integer)
[19:47:38:556] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - <== Total: 1
User(id=1, name=mowenti, password=123456, phone=1111111, nick_name=mingming, create_time=Mon Mar 23 00:00:00 CST 2020)
[19:47:38:558] [DEBUG] - org.apache.ibatis.cache.decorators.LoggingCache.getObject(LoggingCache.java:62) - Cache Hit Ratio [com.matrix.dao.UserMapper]: 0.0
[19:47:38:559] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - ==> Preparing: SELECT id, name, password, phone, nick_name, create_time FROM user
[19:47:38:560] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - ==> Parameters:
[19:47:38:610] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - <== Total: 4
[User(id=1, name=mowenti, password=123456, phone=1111111, nick_name=mingming, create_time=Mon Mar 23 00:00:00 CST 2020), User(id=2, name=liuwenju, password=123456, phone=123456, nick_name=wenwen, create_time=Mon Mar 23 00:00:00 CST 2020), User(id=3, name=liudehua, password=123456, phone=123456, nick_name=liudehua, create_time=Tue Mar 24 00:00:00 CST 2020), User(id=4, name=jack, password=111, phone=111, nick_name=jack, create_time=Fri Jan 02 00:00:00 CST 1970)]
[19:47:38:611] [DEBUG] - org.apache.ibatis.transaction.jdbc.JdbcTransaction.resetAutoCommit(JdbcTransaction.java:123) - Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@56528192]
[19:47:38:658] [DEBUG] - org.apache.ibatis.transaction.jdbc.JdbcTransaction.close(JdbcTransaction.java:91) - Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@56528192]
[19:47:38:662] [DEBUG] - org.apache.ibatis.transaction.jdbc.JdbcTransaction.openConnection(JdbcTransaction.java:137) - Opening JDBC Connection
Sun Apr 05 19:47:38 CST 2020 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
[19:47:39:143] [DEBUG] - org.apache.ibatis.transaction.jdbc.JdbcTransaction.setDesiredAutoCommit(JdbcTransaction.java:101) - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@49b0b76]
// 最后一次查询因为关闭了二级缓存,还是执行了一次SQL
[19:47:39:189] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - ==> Preparing: SELECT id, name, password, phone, nick_name, create_time FROM user WHERE id = ?
[19:47:39:190] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - ==> Parameters: 1(Integer)
[19:47:39:238] [DEBUG] - org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:159) - <== Total: 1
TransactionalCache&TransactionalCacheManager
TransactionalCache和TransactionalCacheManager是CachingExecutor依赖的两个组件。其中,TransactionalCache继承了Cache接口,主要用于保存在某个SqlSession的某个事务中需要向某个二级缓存中添加的缓存数据。TransactionalCache的核心字段的含义如下:
// 底层封装的二级缓存所对应的Cache对象
private final Cache delegate;
// 当该字段为true时,则表示当前TransactionalCache不可查询,且提交事务时会将底层Cache清空
private boolean clearOnCommit;
// 暂时记录添加到TransactionalCache中的数据。在事务提交时,会将其中的数据添加到二级缓存中
private final Map<Object, Object> entriesToAddOnCommit;
// 记录缓存未命中的CacheKey对象
private final Set<Object> entriesMissedInCache;
TransactionalCache.putObject()方法并没有直接将结果对象记录到封装的二级缓存中,而是暂时保存在entriesToAddOnCommit集合中,在事务提交时才会将这些结果对象从entriesToAddOnCommit集合添加到二级缓存中。putObject()方法的具体实现如下:
@Override
public void putObject(Object key, Object object) {
// 将缓存数据存放到暂存区
entriesToAddOnCommit.put(key, object);
}
再来看TransactionalCache.getObject()方法,它首先会查询底层的二级缓存,并将未命中的key记录到entriesMissedInCache中,之后会根据clearOnCommit字段的值决定具体的返回值。
@Override
public Object getObject(Object key) {
// issue #116
// 查询底层的Cache是否包含指定的key
Object object = delegate.getObject(key);
if (object == null) {
// 如果底层缓存对象中不包含该缓存项,则将该key记录到entriesMissedInCache集合中
entriesMissedInCache.add(key);
}
// issue #146
// 如果clearOnCommit为true,则当前TransactionalCache不可查询,始终返回null
if (clearOnCommit) {
return null;
} else {
// 返回从底层Cache中查询到的对象
return object;
}
}
TransactionalCache.clear()方法会清空entriesToAddOnCommit集合,并设置clearOnCommit为true,代码如下:
@Override
public void clear() {
clearOnCommit = true;
entriesToAddOnCommit.clear();
}
TransactionalCache.commit()方法会根据clearOnCommit字段的值决定是否清空二级缓存,然后调用flushPendingEntires()方法将entriesToAddOnCommit集合中记录的结果对象保存到二级缓存中,具体代码实现如下:
public void commit() {
// 在提交事务前,清空二级缓存
if (clearOnCommit) {
delegate.clear();
}
// 将entriesToAddOnCommit集合中的数据保存到二级缓存
flushPendingEntries();
// 重置clearOnCommit为false,并清空entriesToAddOnCommit、entriesMissedInCache集合
reset();
}
private void flushPendingEntries() {
// 将entriesToAddOnCommit添加到二级缓存中
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
// 将entriesMissedInCache中entriesToAddOnCommit为存在的数据添加到二级缓存中
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
TransactionalCache.rollback()方法会将entriesMissedInCache集合中记录的缓存项从二级缓存中删除,并清空entriesToAddOnCommit集合和entriesMissedInCache集合。
public void rollback() {
// 将entriesMissedInCache集合中记录的缓存项从二级缓存中删除
unlockMissedEntries();
// 重置clearOnCommit为false,并清空entriesToAddOnCommit、entriesMissedInCache集合
reset();
}
``
TransactionalCacheManager用于管理CacheingExecutor使用的二级缓存对象,其中只定义了一个transactionalCaches字段,(HashMap<Cache, TransactionalCache>类型),它的key是对应的CachingExecutor使用的二级缓存对象,value是相应的TransactionalCache对象,在该TransactionalCache中封装了对应的二级缓存对象,也就是key。
TransactionalCacheManager的各个方法如下:
(1)、clear()、putObject()、getObject()方法:调用指定二级缓存对应的TransactionalCache对象的对应方法,如果TransactionalCaches集合中没有对应的TransactionalCache对象,则通过getTransactionalCache()方法创建。
```java
private TransactionalCache getTransactionalCache(Cache cache) {
// 从缓存中获取
TransactionalCache txCache = transactionalCaches.get(cache);
if (txCache == null) {
// 如果没有获取到则直接创建TransactionalCache对象
txCache = new TransactionalCache(cache);
// 添加到transactionalCaches集合
transactionalCaches.put(cache, txCache);
}
return txCache;
}
(2)、commit()方法、rollback()方法:遍历transactionalCaches集合,并调用其中各个TransactionCache对象的相应方法。
CachingExecutor的实现:
CachingExecutor中封装了一个用于执行数据库操作的Executor对象,以及一个用于管理缓存的TransactionalCacheManager对象。
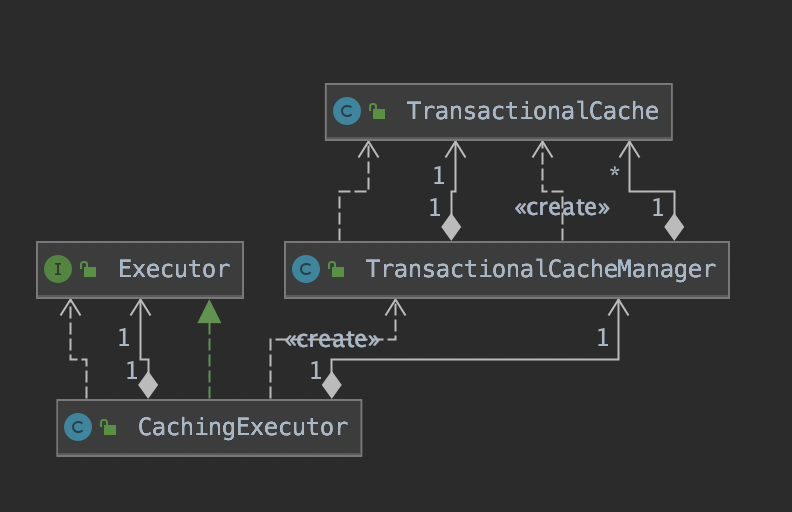
CachingExecutor.query()方法执行的查询操作步骤如下:
(1)、获取BoundSql对象,创建查询语句对应的CacheKey对象。
(2)、检测是否开启了二级缓存,如果没有开启二级缓存,则直接调用底层Executor对象的query()方法查询数据库。如果开启了二级缓存,则继续后面的步骤。
(3)、检测查询操作是否包含输出类型的参数,如果是这种情况,则报错。
(4)、调用TransactionalCacheManager的getObject()方法查询二级缓存,如果二级缓存中查找到相应的结果对象,则直接将该结果对象返回。
(5)、如果二级缓存没有相应结果对象,则调用底层的Executor对象的query()方法,正如前面介绍的,它会先查询一级缓存,一级缓存未命中时,才会查询数据库。最后还会将得到的结果对象放入TransactionalCache.entriesToAddOnCommit集合中保存。
query具体代码如下:
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
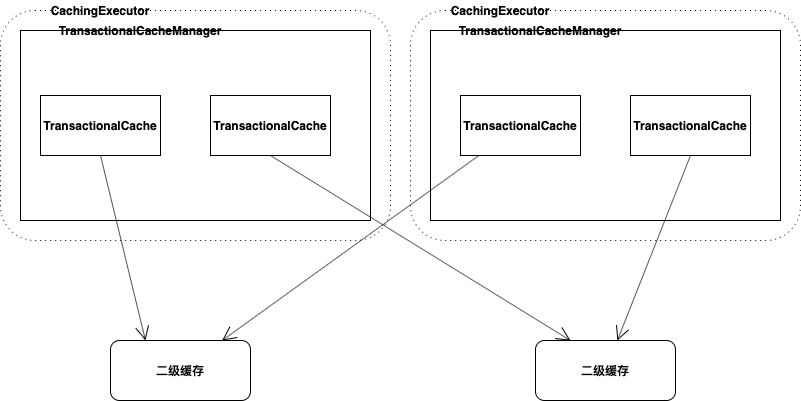
CachingExecutor、TransactionalCacheManager、TransactionalCache以及二级缓存之间的关系如下:
1.3、SqlSession
SqlSession是Mybatis核心接口之一,也是Mybatis接口层的主要组成部分,对外提供Mybatis常用API。Mybatis提供了两个SqlSession接口的实现,这里是用了工厂方法模式。默认情况下,使用的是DefaultSqlSession。
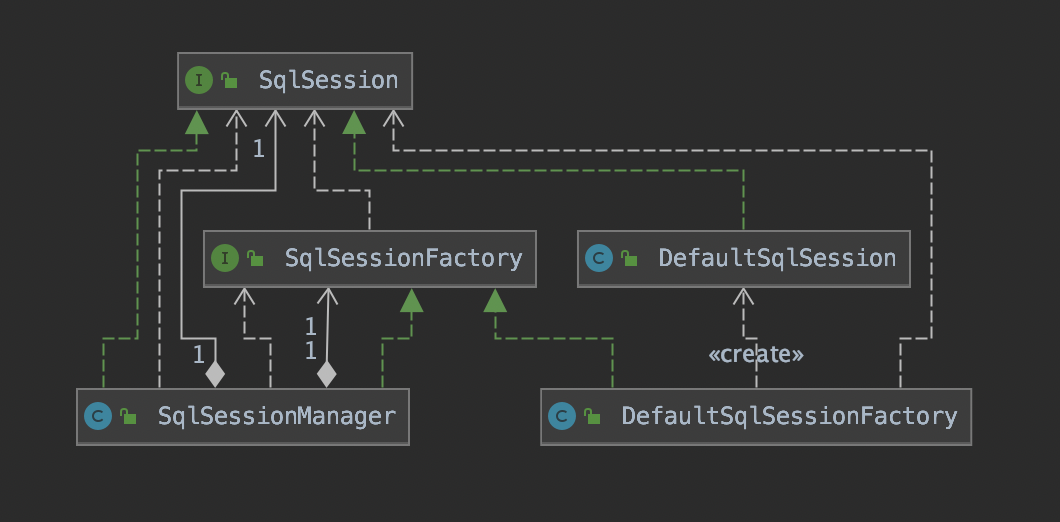
SqlSessionFactory负责创建SqlSession对象,其中包含了多个openSession()方法的重载,可以通过其参数执行事务的隔离级别、底层调用Executor的类型以及是否自动提交事务等方面的配置。
2、MapperProxyFactory
mybatis的用法:
Reader reader = Resources.getResourceAsReader("mybatis-config.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader);
SqlSession sqlSession = factory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user = userMapper.getUserById(1);
System.out.println(user);
List<User> users = userMapper.listAllUser();
System.out.println(users);
用户一般使用SqlSession来获取Mapper接口。
SqlSession的getMapper()方法如下:
@Override
public <T> T getMapper(Class<T> type) {
// 调用Configuration的getMapper
return configuration.<T>getMapper(type, this);
}
Configuration的getMapper()方法:
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
MapperRegistry的getMapper()方法:
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
// 从缓存中获取启动时注册的MapperProxyFactory
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
// 调用MapperProxyFactory的newInstance方法
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
MapperProxyFactory的newInstance()方法如下:
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
protected T newInstance(MapperProxy<T> mapperProxy) {
// 通过JDK动态代理来创建代理类
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
MapperProxy实现了InvocationHandler接口,那么当代理类对象的方法被调用时会调用MapperProxy的invoke方法。代码如下:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 如果是Object类的方法,直接执行
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else if (isDefaultMethod(method)) {
// 对于动态类型语言的支持
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
// 从缓存中获取MapperMethod对象,如果缓存中没有,则创建新的MapperMethod对象并添加到缓存中
final MapperMethod mapperMethod = cachedMapperMethod(method);
// 执行MapperMethod的execute方法
return mapperMethod.execute(sqlSession, args);
}
2.1、创建MapperMethod对象
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {
this.command = new SqlCommand(config, mapperInterface, method);
this.method = new MethodSignature(config, mapperInterface, method);
}
在MapperMethod类中维护了两个字段:
private final SqlCommand command;
private final MethodSignature method;
SqlCommand的构造函数如下:
public SqlCommand(Configuration configuration, Class<?> mapperInterface, Method method) {
// 获取方法名
final String methodName = method.getName();
// 获取方法所在的class类
final Class<?> declaringClass = method.getDeclaringClass();
// 获取该接口方法的SQL信息
MappedStatement ms = resolveMappedStatement(mapperInterface, methodName, declaringClass,
configuration);
if (ms == null) {
if (method.getAnnotation(Flush.class) != null) {
name = null;
type = SqlCommandType.FLUSH;
} else {
throw new BindingException("Invalid bound statement (not found): "
+ mapperInterface.getName() + "." + methodName);
}
} else {
name = ms.getId();
type = ms.getSqlCommandType();
if (type == SqlCommandType.UNKNOWN) {
throw new BindingException("Unknown execution method for: " + name);
}
}
}
看下resolveMappedStatement方法:
private MappedStatement resolveMappedStatement(Class<?> mapperInterface, String methodName,
Class<?> declaringClass, Configuration configuration) {
// 拼装statementID,interfaceName.methodName
String statementId = mapperInterface.getName() + "." + methodName;
// 判断Configuration中是否存在这个statementId
if (configuration.hasStatement(statementId)) {
return configuration.getMappedStatement(statementId);
} else if (mapperInterface.equals(declaringClass)) {
return null;
}
for (Class<?> superInterface : mapperInterface.getInterfaces()) {
if (declaringClass.isAssignableFrom(superInterface)) {
MappedStatement ms = resolveMappedStatement(superInterface, methodName,
declaringClass, configuration);
if (ms != null) {
return ms;
}
}
}
return null;
}
2.2、执行MapperMethod对象的execute方法
MapperMethod的execute方法如下:
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
// 获取执行SQL类型
switch (command.getType()) {
// SQL类型是INSERT
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
// SQL类型是UPDATE
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
// SQL类型是DALETE
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
// SQL类型是SELECT
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
}
break;
// SQL类型是FLUSH
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
// 返回执行结果
return result;
}
在MapperMethod的execute方法中使用了SqlSession的对应的操作数据库方法:
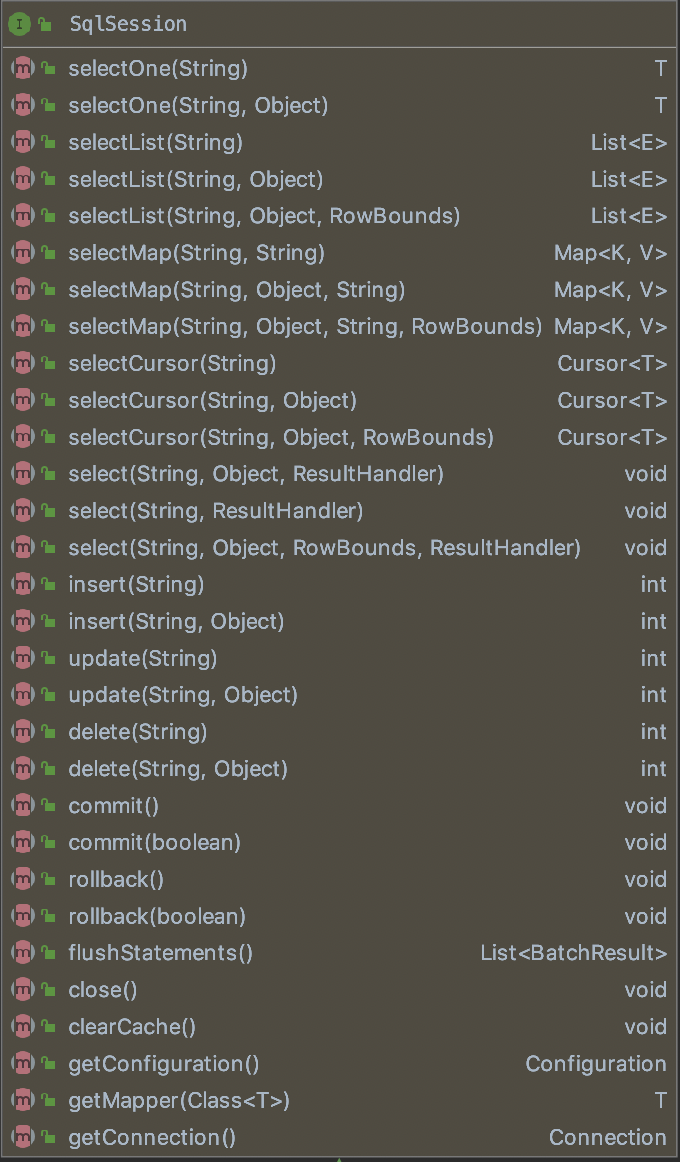
其子类DefaultSqlSession类的方法和字段如下所示:
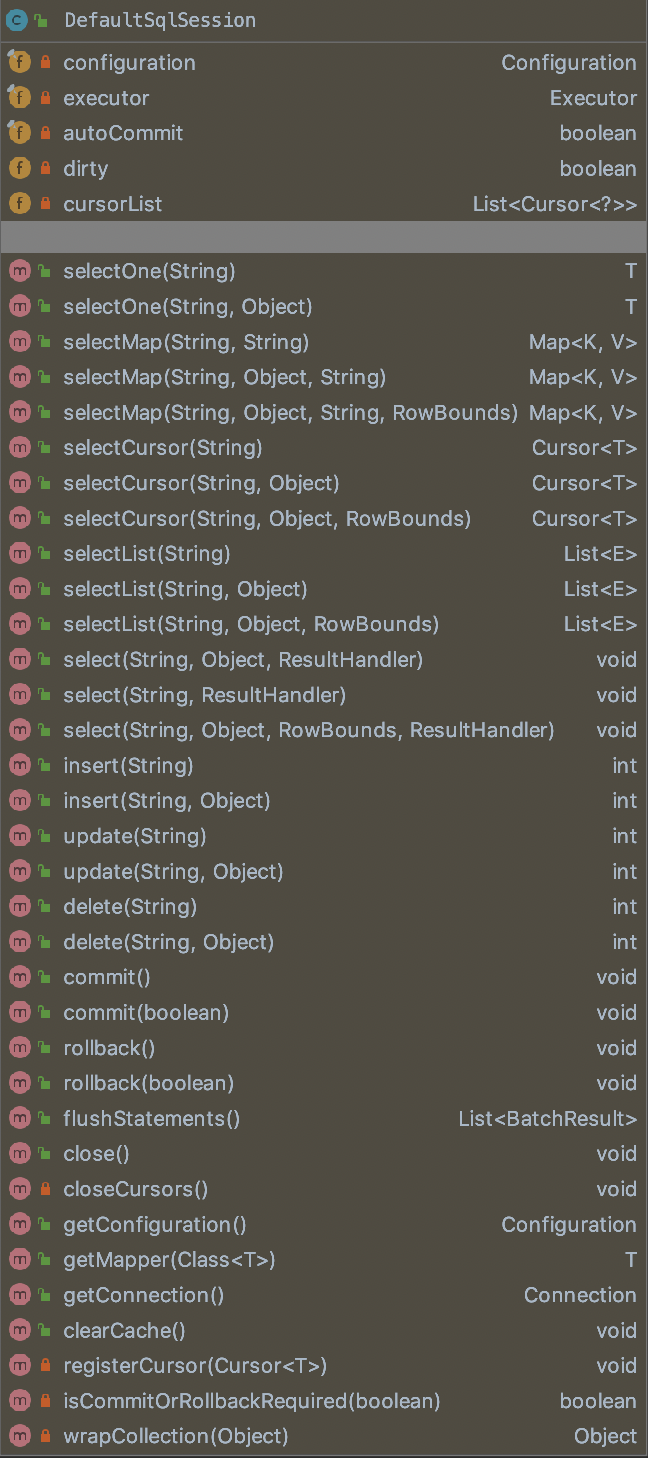
这里以selectList为例,说明下整体的调用路径。
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
// 从Configuration中获取MappedStatement,这里的statement参数代表这次mapper中的id。
MappedStatement ms = configuration.getMappedStatement(statement);
// 通过Executor的query方法
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
Executor中的query方法如下所示:
BaseExecutor中的query方法
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 获取BoundSql
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
// 调用query
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 从一级缓存中获取结果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 调用queryFromDatabase来执行查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 执行子类的doQuery来获取查询结果
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
SimpleExecutor中的doQuery方法如下:
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
// 获取Configuration
Configuration configuration = ms.getConfiguration();
// 创建StatementHandler
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 调用prepareStatement()方法
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行Handler的query方法
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
// 调用StatementHandler的prepare方法
stmt = handler.prepare(connection, transaction.getTimeout());
// 执行parameterize方法
handler.parameterize(stmt);
return stmt;
}
@Override
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
// 创建Statement对象
statement = instantiateStatement(connection);
// 设置Statement的超时时间
setStatementTimeout(statement, transactionTimeout);
// 设置Statement的fetchSize
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
instantiateStatement方法如下:
@Override
protected Statement instantiateStatement(Connection connection) throws SQLException {
// 获取Sql语句
String sql = boundSql.getSql();
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
// 创建Statement对象
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() != null) {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
} else {
return connection.prepareStatement(sql);
}
}
@Override
public void parameterize(Statement statement) throws SQLException {
parameterHandler.setParameters((PreparedStatement) statement);
}
PreparedStatementHandler类的handler方法
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 执行execute方法
ps.execute();
// 调用resultSetHandler执行处理结果
return resultSetHandler.<E> handleResultSets(ps);
}
resetSetHandler的handlerResultSets方法如下:
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt);
// 获取Configuration中的ResultMap对象
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}
至此整个代码调用链已经调用完成,下面是binding的整体业务及分层图: