
外连接消除
前文说过,内连接的驱动表和被驱动表的位置可以相互交换,而左外连接和右外连接的驱动表与被驱动表是固定的。这就导致了内连接可以通过优化表的连接顺序来降低整体的查询成本,而外连接却无法优化表的连接顺序。
外连接和内连接的本质区别就是:对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配ON子句中过滤条件的记录,那么该驱动表记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL值填充;而内连接的驱动表的记录如果无法在被驱动表中找到匹配ON子句中过滤条件的记录,那么该驱动表记录会被舍弃。
我们知道,凡是不符合WHERE子句中条件的记录都不会参与连接。只要我们在WHERE子句的搜索条件中指定被驱动表的列不为NULL的搜索条件,那么外连接中在被驱动表中找不到符合ON子句条件的驱动表记录也就从最后的结果集中被排除了。也就是说,在这种情况下,外连接和内连接也就没有什么区别了。
我们把这种在外连接查询中,指定的WHERE子句中包含被驱动表中的列不为NULL值的条件称为空值拒绝(reject-NULL)。在被驱动表的WHERE子句符合空值拒绝的条件后,外连接和内连接可以相互转换。这种转换带来的好处就是优化器可以通过评估表的不同连接顺序的成本,选出成本最低的连接顺序来执行查询。
子查询优化
子查询语法
在一个查询语句中的某个位置也可以有另一个查询语句,这个出现在某个查询语句的某个位置中的查询就称为子查询,子查询可以在一个外层查询的各种位置出现。
- 在SELECT子句中
SELECT (SELECT m1 FROM t1 LIMIT 1);
其中SELECT m1 FROM t1 LIMIT 1就是子查询。
- 在FROM子句中
SELECT m,n FROM (SELECT m2 + 1 AS m. n2 AS n FROM t2 WHERE m2 > 2) AS t;
这里可以把子查询的查询结果当作一个表。子查询后边的AS t表明这个子查询的结果就相当于一个名称为t的表,这个名为t的表的列就是子查询结果中的列。MySQL把这种放在FROM子句后面的子查询称为派生表。
- 在WHERE或ON子句中
SELECT * FROM t1 WHERE m1 IN (SELECT m2 FROM t2);
1、按照返回的结果集区分子查询
因为子查询本身也是一个查询,所以按照它们返回的不同结果集类型而把这些子查询分为不同的类型。
- 标量子查询:那些只返回一个单一值的子查询称为标量子查询。
比如:
SELECT (SELECT m1 FROM t1 LIMIT 1);
或者下面这样:
SELECT * FROM t1 where m1 = (SELECT MIN(m2) FROM t2);
这两个查询语句中的子查询都返回一个单一的值(也就是一个标量)。这些标量子查询可以作为一个单一值或者表达式的一部分出现在查询语句的各个地方。
- 行子查询:顾名思义,就是返回一条记录的子查询,不过这条记录需要包含多个列。
比如下面这样:
SELECT * FROM t1 WHERE (m1,n1) = (SELECT m2,n2 FROM t2 LIMIT 1);
其中 (SELECT m2,n2 FROM t2 LIMIT 1)就是一个行子查询。
- 列子查询:就是查询出一个列的数据,不过这个列的数据需要包含多条记录。
比如下面这样
SELECT * FROM t1 WHERE m1 IN (SELECT m2 FROM t2);
其中(SELECT m2 FROM t2)就是一个列子查询,表明将查询出的表t2的m2列的值作为外层查询IN语句的参数。
- 表子查询:就是子查询的结果既包含很多条记录,又包含很多个列。
比如下面这样
SELECT * FROM t1 WHERE (m1,n1) IN (SELECT m2,n2 FROM t2);
其中(SELECT m2,n2 FROM t2)就是一个表子查询。
2、按与外层查询的关系来区分子查询
- 不相关子查询:如果子查询可以单独运行出结果,而不依赖于外层查询的值,我们就可以把这个查询称为不相关子查询。
- 相关子查询:如果子查询的执行需要依赖于外层查询的值,我们就可以把这个子查询称为相关子查询。
SELECT * FROM t1 WHERE m1 IN (SELECT m2 FROM t2 WHERE n1 = n2);
3、子查询在布尔表达式中的使用
- 使用=、>、<、>=、<=、<>、!=、<=>作为布尔表达式的操作符
- [NOT] IN/ANY/SOME/ALL子查询
- IN或者NOT IN
- ANY/SOME
- ALL
- EXISTS子查询
4、子查询语法注意事项 - 子查询必须用小括号括起来
- 在SELECT子句中的子查询必须是标量子查询
- 要想得到标量子查询或者行子查询,但又不能保证子查询的结果集只有一条记录时,应该使用LIMIT1来限制记录数量
- 对于[NOT] IN/ANY/SOME/ALL子查询来说,子查询中不允许有LIMIT语句
- 不允许在一条语句中增删改某个表的记录时,同时还对该表进行子查询
子查询在MySQL中是怎么执行的
1、子查询执行方式
- 如果该子查询是不相关子查询,比如下面这个查询:
SELECT * FROM s1 WHERE key1 IN (SELECT common_field FROM s2);
它的执行方式是这样的。
步骤1、先单独执行(SELECT common_field FROM s2)子查询。
步骤2、然后将子查询得到的结果当作外层查询的参数,再执行外层查询SELECT * FROM s1 WHERE key1 IN (…)。
- 如果该子查询是相关子查询,比如下面这个查询:
SELECT * FROM s1 WHERE key1 IN (SELECT common_field FROM s2 WHERE s1.key2 = s2.key2);
这个查询语句的子查询出现了s1.key1 = s2.key2这样的条件,这意味着该子查询依赖外层查询的值。
步骤1、先从外层查询中获取一条记录。
步骤2、然后从获取的这条记录中找出子查询中涉及的值。
步骤3、最后根据子查询的查询结果来检测外层查询WHERE子句的条件是否成立。如果成立,就把外层查询的那条记录加入到结果集,否则就丢弃。
步骤4、重复执行步骤1,获取第二条外层查询中的记录;以此类推。
2、标量子查询、行子查询的执行方式
SELECT * FROM s1 WHERE key1 = (SELECT common_field FROM s2 WHERE key3 = 'a' LIMIT 1);
步骤1、单独执行(SELECT common_field FROM s2 WHERE key3 = ‘a’ LIMIT 1)这个子查询。
步骤2、然后将子查询得到的结果当作外层查询的参数,再执行外层查询SELECT * FROM s1 WHERE key1 =。
也就是说,对于包含不相关标量的子查询或者行子查询的查询语句来说,MySQL会分别独立执行外层查询和子查询-当作两个表查询就好了。
3、IN子查询优化
(1)物化表的提出
对于不相关的IN子查询,比如下面这样:
SELECT * FROM s1 WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = 'a');
我们最开始的感觉就是,这种不相关的IN子查询的执行方式,与不相关的标量子查询或者行子查询一样,都是外层查询和子查询当作两个独立的单表查询来对待。遗憾的是,事情并不是我们想象的样子。整个执行过程并没有我们想象的那么简单。
对于不相关的IN子查询,如果子查询结果集中的记录条数很少,那么把子查询和外层查询分别看成两个单独的单表查询,效率还是蛮高的。但是,如果单独执行子查询后的结果集太多,就会导致下面这些问题。
- 结果集太多,可能内存都放不下。
- 对于外层查询来说,如果子查询的结果集太多,则意味着IN子句中的参数特别多,这将导致:
- 无法有效地使用索引,只能对外层查询进行全表扫描
- 在对外层查询执行全表扫描时,如果IN子句中的参数太多,会导致在检测一条记录的IN表达式是否为TRUE时花费太多的时间。
假设IN子句中的参数只有两个:
SELECT* FROM tb1_name WHERE column IN (a,b);
这样就相当于针对tb1_name表中的每条记录,相当于都要判断它的column列是否符合column = a OR column = b条件。当IN子句中的参数比较少时,这并不是什么问题。
如果IN子句中的参数比较多,比如下面这样:
SELECT * FROM tb1_name WHERE column IN (a,b,c,...);
这样一来,相当于每条记录都需要判断它的column列是否符合column = a OR column = b OR column = c OR …条件,这样就性能耗费多了。
于是MySQL想出了一招:不直接将不相关子查询的结果集当作外层查询的参数,而是将该结果集写入一个临时表中。在将结果集写入临时表时,有两点注意事项:
1、该临时表的列就是子查询结果集中的列。
2、写入临时表的记录会被去重。
前文讲到,IN语句是用来判断某个操作数是否在于某个集合中,集合中的值是否重复对整个IN语句的结果来说并没有啥关系。在将结果集写入临时表时,对记录进行去重可以让临时表变得更小,从而节省空间。
一般情况下,子查询结果集不会大得离谱,所以会为它建立基于内存的使用MEMORY存储引擎的临时表,而且会为该表建立哈希索引。
IN语句的本质就是判断某个操作数是否存在于某个集合中。如果集合中的数据建立了哈希索引,那么这个判断匹配的过程就相当快。
如果子查询的结果集非常大,超过了系统变量tmp_table_size或者max_heap_table_size的值,临时表会转而使用基于磁盘的存储引擎来保存结果集中的记录,索引类型也相应地转变为B+树索引。
MySQL将子查询结果集中的记录保存到临时表的过程称为物化(materialize)。方便起见,我们就把那个存储子查询结果集的临时表称为物化表。正因为物化表中的记录都建立了索引(基于内存的物化表有哈希索引,基于磁盘的物化表有B+树索引),通过索引来判断某个操作数是否在子查询结果集中时,速度会变得非常快,从而提升了子查询语句的性能。
(2)物化表转连接
SELECT * FROM s1 WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = 'a');
当把子查询物化之后,假设子查询物化表的名称为materialized_table,该物化表存储的子查询结果集的列为m_val,那么这个查询可以从下面两个角度来看待。
- 从表s1的角度来看待:整个查询的意思是,对于s1表中的每条记录来说,如果该记录的key1列的值在子查询对应的物化表中,则该记录会被加入到最终的结果集。如下图所示:
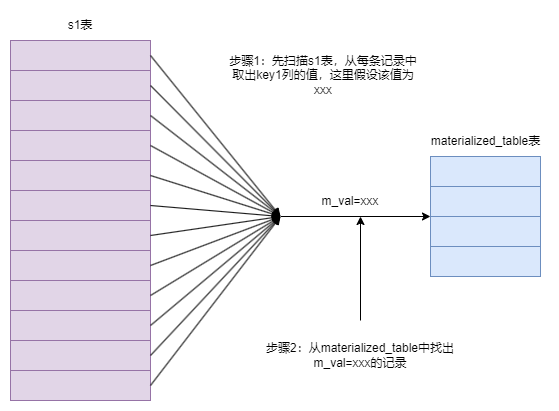
- 从子查询物化表的角度来看待:整个查询的意思是,对于子查询物化表的每个值来说,如果能在s1表中找到对应的key1列的值与该值相等的记录,那么就把这些记录加入到最终的结果集,如下图:
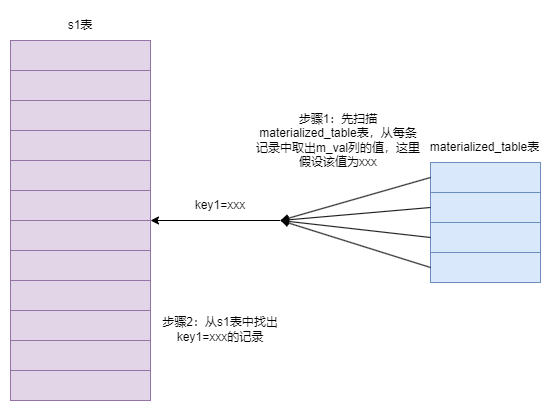
也就是说,上面的查询其实相当于表s1与子查询物化表materialized_table进行内连接:
SELECT s1.* FROM s1 INNER JOIN materialized_table ON key1 = m_val;
转化成内连接之后就有意思了。查询优化器可以评估不同连接顺序需要的成本是多少,然后从中选取成本最低的那种方式执行查询。我们分析一下上述查询中使用外层查询的表s1和物化表materialized_table进行内连接的成本都是由哪几部分组成的。
如果使用s1表作为驱动表,总查询成本由下面几部分组成:
- 物化子查询时需要的成本。
- 扫描s1表时的成本。
- s1表中的记录数量*通过条件m_val=xxx对materialized_table表进行单表访问的成本。
如果使用materialized_table表作为驱动表,总查询成本由下面几部分组成:
- 物化子查询时需要的成本。
- 扫描物化表时的成本。
- 物化表中的记录数量*通过条件key1=xxx对s1表进行单表访问的成本。
MySQL优化器会通过运算来选择成本更低的方案执行查询。
(3)将子查询转换为半连接
下面这条语句
SELECT * FROM s1 WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = 'a');
可以把这个查询理解成:对于s1表中的某条记录,如果能在s2表中找到一条或多条记录,这些记录的common_field的值等于s1表记录的key1列的值,那么该条s1表的记录就会被加入到最终的结果集。这个过程其实与把s1和s2两个表连接起来的效果很像。
SELECT s1.* FROM s1 INNER JOIN s2 ON (s1.key1 = s2.common_field WHERE s2.key3 = 'a');
只不过我们不能保证对于s1表的某条记录来说,在s2表中有多少条记录满足s1.key1=s2.common_field条件。不过可以分3种情况进行讨论。
- 情况1:对于s1表中的某条记录来说,s2表中没有任何记录满足s1.key1=s2.common_field条件,那么该记录自然也不会加入到最终的结果集。
- 情况2:对于s1表中的某条记录来说,s2表中有且只有一条记录满足s1.key1=s2.common_field条件,那么该记录会被加入到最终的结果集。
- 情况3:对于s1表中的某条记录来说,s2表中至少有2条记录满足s1.key1=s2.common_field条件,那么该记录会被多次加入最终的结果集。
对于s1表中的某条记录来说,由于我们只关心s2表中是否存在记录满足s1.key1=s2.common_field条件,而不关心具体有多少条记录与之匹配;又因为情况3的存在,因此前文所说的包含IN子查询的查询和两表连接查询之间并不完全等价。但是将子查询转换为连接又确实可以充分发挥优化器的作用,所以MySQL在这里提出了一个概念半连接(semi-join)。将s1表和s2表进行半连接的意思就是:对于s1表中的某条记录来说,我们只关心s2表中是否存在与之匹配的记录,而不关心具体有多少条记录与之匹配,最终的结果集中只保留s1表的记录。
SELECT s1.* FROM s1 SEMI JOIN s2 ON s1.key1 = s2.common_field WHERE key3 = 'a';
MySQL怎么实现这种半连接呢?
- Table pullout(子查询中的表上拉)
当子查询的查询列表处只有主键或者唯一索引列时,可以直接把子查询中的表上拉到外层查询的FROM子句中,并把子查询中的搜索条件合并到外层查询的搜索条件中。比如下面这个查询语句中:
SELECT * FROM s1 WHERE key2 IN (SELECT key2 FROM s2 WHERE key3 = 'a');
由于key2列是s2表的唯一索引列,所以可以直接把s2表上拉到外层查询的FROM子句中,并且把子查询中的搜索条件合并到外层查询的搜索条件中。上拉之后的查询就是下面这样:
SELECT s1.* FROM s1 INNER JOIN s2 ON (s1.key2 = s2.key2) where s2.key3 = 'a';
- Duplicate Weedout(重复值消除)
对于下面这个查询
SELECT * FROM s1 WHERE key2 IN (SELECT common_field FROM s2 WHERE key3 = 'a');
在转换为半连接查询后,s1表中的某条记录可能在s2表中有多条匹配的记录,所以该条记录可能多次被添加到最后的结果集中。为了消除重复,我们可以建立一个临时表,比如这个临时表如下所示:
CREATE TABLE tmp (id INT PRIMARY KEY);
这样在执行连接查询的过程中,每当某条s1表中的记录要加入到结果集时,就首先把这条记录的id值加入到这个临时表中。如果添加成功,则说明之前这条s1表中的记录并没有加入最终的结果集,现在把该条记录添加到最终的结果集;如果添加失败,则说明这条s1表中的记录之前已经加入到最终的结果集,这里直接把它丢弃就好了。这种使用临时表消除半连接结果集中重复值的方式称为Duplicate Weedout(重复值消除)。
- LooseScan(松散扫描)
对于下面这个查询:
SELECT * FROM s1 WHERE key3 IN (SELECT key1 FROM s2 WHERE key1 > 'a' AND key1 < 'b');
在子查询中,对于s2表的访问可以使用到key1列的索引,而子查询的查询列表处恰好就是key1列。这样在将该查询转换为半连接查询后,如果将s2作为驱动表执行查询,那么执行过程如下图所示:
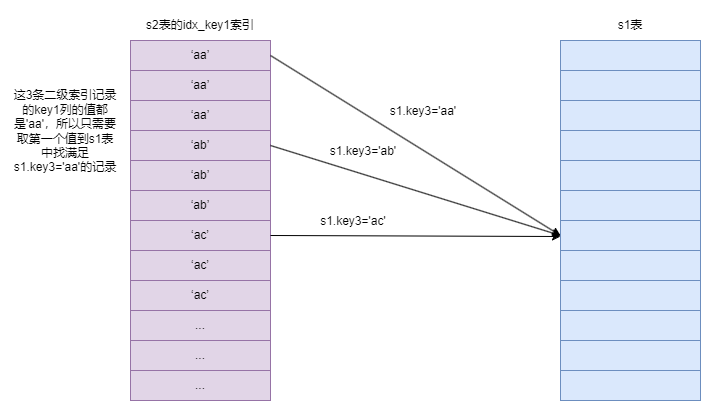
从图中可以看到,在s2表的idx_key1索引中,值为’aa’的二级索引记录一共有3条。只需要取第一条的值到s1表中查找s1.key3 = 'aa’的记录。如果能在s1表中找到对应的记录,就把对应的值到s1表中找匹配的记录。这种虽然是扫描索引,但只取键值相同的第一条记录去执行匹配操作的方式称为LooseScan。
- Semi-join materialization(半连接物化)
- FirstMatch(首次匹配)
总结一下,只有符合下面这些条件的子查询才可以转换为半连接:
- 该子查询必须是与IN操作符组成的布尔表达式,并且在外层查询的WHERE或者ON子句中出现。
- 外层查询也可以有其他的搜索条件,不能是由UNION连接起来的若干个查询。
- 该子查询必须是一个单一的查询,不能是由UNION连接起来的若干个查询。
- 该子查询不能包含GROUP BY、HAVING语句或者聚集函数。