
1、redis的5种基础数据结构
Redis有5种基础数据结构,分别为:string(字符串)、list(列表)、hash(字典)、set(集合)和zset(有序集合)。
1.1、string(字符串)
字符串string是redis种最简单的数据结构,它的内部表示就是一个字符数组。

redis所有的数据结构都以唯一的key字符串作为名称,然后通过这个唯一key值来获取相应的value数据,不同类型的数据结构的差异就在于value的结构不一样。
Redis的字符串是动态字符串,是可以修改的字符串,内部结构的实现类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,如下所示:

内部为当前字符串分配的实际空间capacity一般要高于实际字符串长度len。当字符串长度小于1MB时,扩容都是加倍现有的空间。如果字符串高于1MB。扩容时一次只会多扩1MB的空间,需要注意的是字符串最大长度为512MB。
- 键值对:相当于字典的key和value,支持简单的增删改查操作。
- 批量键值对:可以对多个字符串进行批量读写,节省网络开销。
- 过期和set命令扩展:可以对key设置过期时间,到时间会自动删除,这个功能常用来控制缓存的失效时间。
- 计数:如果value值是一个整数,还可以对它进行自增操作。自增是有范围的,它的范围在signed long的最大值和最小值之间,超出了这个范围,Redis会报错。
1.2、list(列表)
Redis的列表相当于Java语言里面的LinkedList,注意它是链表而不是数组。这意味着list的插入和删除操作非常快,时间复杂度为O(1),但是索引定位很慢,时间复杂度为O(n)。如下图所示,列表中的每个元素都使用双向指针顺序,串起来可以同时支持前向后向遍历。

redis的列表结构常用来做异步队列使用。将需要延后处理的任务结构体序列化成字符串,塞进redis的列表,另一个线程从这个列表中轮询数据进行处理。
- 右边进左边出:队列,是先进先出的数据结构,常用于消息排队和异步逻辑处理,它会确保元素的访问顺序性。
- 右边进右边出:栈,是先进后出的数据结构,跟队列相反。
lindex相当于Java链表的get(int index)方法,它需要对链表进行遍历,性能随着参数index的增大而变差。
1.2.1、快速列表
redis的底层存储不是一个简单的linkedlist,而是称之为快速链表(quicklist)的一个结构。
首先在列表元素较少的情况下,会使用一块连续的内存存储,这个结构是ziplist,即压缩列表。它将所有的元素彼此紧凑着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针空间太大,会浪费空间,还会加重内存的碎片化,比如某普通链表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。所以Redis将链表和ziplist结合起来组成quicklist,也就是将多个ziplist使用双向指针串起来使用。

1.3、hash(字典)
Redis的字典相当于Java语言里面的HashMap,它是无序字典,内部存储了很多键值对。实现结构上与Java的HashMap也是一样的,都是数组加链表的二维结构,第一维hash数组位置发生碰撞时,就会将碰撞的元素使用链表串接起来。
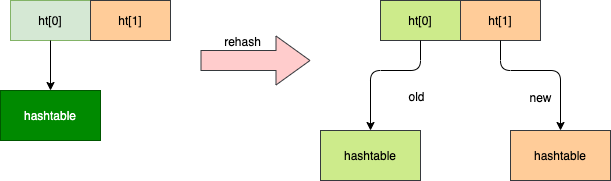
不同的是,Redis的字典的值只能是字符串,另外它们rehash的方式不一样,因为Java的HashMap在字典很大时,rehash是个耗时操作,需要一次性全部rehash。Redis为了追求高性能,不能阻塞服务,所以采用了渐进式rehash策略。
渐进式rehash会在rehash的同时,保留新旧两个hash结构,如图所示,查询时会同时查两个hash结构,然后在后续的定时任务以及hash操作指令中,循序渐进地将旧hash的内容一点点地迁移到新的hash结构中。当迁移完成了,就会使用新的hash结构取而代之。
当hash移除了最后一个元素之后,该数据结构被自动删除,内存被回收。
hash结构也可以用来存储用户信息,与字符串需要一次性全部序列化整个对象不同,hash可以对用户结构中的每个字段单独存储。这样当我们需要获取用户信息时可以进行部分获取。而以整个字符串的形式去保存用户信息的话,就只能一次性全部读取,这样就会浪费网络流量。
hash也有缺点,hash结构的存储消耗要高于单个字符串。
1.4、set(集合)
Redis的集合相当于Java语言里面的HashSet,它内部的键值对是无序的、唯一的。它的内部实现相当于一个特殊的字典,字典中所有的value都是一个值NULL。
当集合中最后一个元素被移除之后,数据结构被自动删除,内存被回收。
1.5、zset(有序列表)
它类似于Java的SortedSet和HashMap的结合体,一方面它是一个set,保证了内部value的唯一性,另一方面它可以给每个value赋予一个score,代表这个value的排序权重。它的内部实现用的是一种跳跃列表的数据结构。
zset中最后一个value被移除后,数据结构被自动删除,内存被回收。
2、分布式锁
2.1、分布式锁的意义
分布式锁本质上要实现的目的就是在Redis里面占一个位置,当别的进程也要来占位置时,发现已经被抢占,然后放弃或者重试。
占位置一般使用setnx指令,只允许被一个客户端占位置。先来先占,用完了,再调用del指令释放位置。
但是有个问题,如果执行逻辑到中间出现了异常,可能会导致del指令没有被调用,这样就会陷入死锁,锁永远得不到释放。于是我们在拿到锁之后,再给锁加上一个过期时间,这样即使中间出现异常也可以保证之后锁会自动释放。
但是还有一个问题,setnx和expire是两条指令而不是原子指令。如果两条逻辑可以一起执行就不会出现问题。为了解决这个问题。redis2.8版本中,使用set lock:*** true ex 5 nx
2.2、超时问题
Redis的分布式锁不能解决超时问题,如果在加锁和释放锁之间的逻辑执行的太长,以至于超出了锁的超时限制,就会出现问题。因为第一个线程持有的锁过期了,临界区的逻辑还没执行完,而同时第二个线程就提前重新持有了这把锁,导致临界区代码不能得到严格串行执行。
为了避免这个问题,Redis分布式锁不要用于较长时间的任务。
2.3、可重入性
可重入性是指线程在持有锁的情况下再次请求加锁,如果一个锁支持统一线程的多次加锁,那么这个锁就是可重入的。
4、延时队列
4.1、异步消息队列
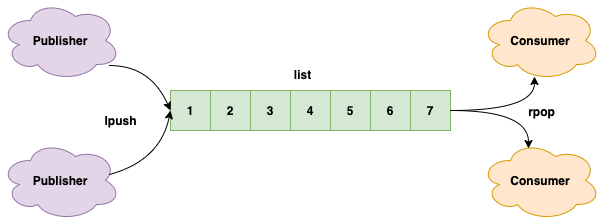
Redis的list(列表)数据结构常用来作为异步消息队列使用,用rpush和lpush操作入队列,用lpop和rpop操作出队列。
它可以支持多个生产者和多个消费者并发进出消息,每个消费者拿到的消息都是不同的列表元素。
4.2、队列空了怎么办
客户端通过队列的pop操作来获取消息,然后进行处理。处理完了再接着获取消息,在进行处理。如此循环,这便是作为消息队列消费者的客户端的生命周期。
可是如果队列空了,客户端就会陷入pop的死循环,不停地pop,没有数据,接着再pop,还没有数据。这就是浪费生命周期的空轮询。空轮询不但拉高了客户端的CPU消耗,Redis的QPS也会被拉高,如果这样空轮询的客户端有几十个,Redis的慢查询可能会显著很多。
通常我们使用sleep来解决这个问题,让线程睡一会儿,客户端的CPU降下来了,Redis的QPS爷降下来了。
4.3、阻塞读
阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。消息的延迟几乎为零。用blpop/brpop替代前面的lpop/rpop,就完美解决了上面的问题。
4.4、空闲连接自动断开
上面的阻塞读还存在一个问题就是空闲连接的问题。
如果线程一直阻塞在那里,Redis的客户端连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,检查闲置资源占用。这个时候blpop/brpop会抛出异常。
4.5、锁冲突处理
如果客户端在处理请求时加锁没加成功怎么办。一般有以下3种策略来处理加锁失败。
(1)、直接抛出异常
(2)、sleep一会儿,然后再重试
(3)、将请求转移至延时队列,过一会儿再试
4.6、延时队列的实现
延时队列通过Redis的zset来实现。将消息序列化一个字符串作为zset的value,这个消息的到期处理时间作为score,然后用多个线程轮询zset获取到期的任务进行处理。
5、位图
Redis中提供了位图数据结构。它的内容其实就是普通的字符串,也就是byte数组。我们可以使用普通的get/set直接获取和设置整个位图的内容,也可以使用位图操作getbit/setbit等将byte数组看成位数组来处理。
5.1、基本用法
Redis的位数组是自动扩展的,如果设置了某个偏移位置超出了现有的内容范围,就会自动将位数组进行零扩充。
6、漏斗限流
漏斗的容量是有限的,如果将漏嘴堵住,然后一直往里面灌水,它就会变满,直至再也装不进去。如果将漏嘴放开,水就会往下流,流走一部分之后就又可以继续往里面灌水。如果漏嘴流水的速率大于灌水的速率,那么漏斗永远都装不满。如果漏嘴流水速率小于灌水速率。那么一旦漏斗满了,灌水就需要暂停并等待漏斗腾出一部分空间。
6.1、Redis-Cell
Redis4.0提供了一个限流Redis模块,它叫Redis-cell。该模块也使用了漏斗算法,并提供了原子的限流指令。cl.throttle gm:reply 15 30 60 1
15代表漏斗初始容量
30和60代表60秒内允许30个操作,这是漏斗速率
返回值如下:
0表示允许,1表示拒绝
漏斗容量
漏斗剩余空间
如果被拒绝了需要多长时间合适
多长时间后,漏斗完全空出来
7、scan基本用法
scan提供了三个参数,第一个是cursor整数值,第二个是key的正则模式,,第三个是遍历的limit hint。
布隆过滤器的原理
每个布隆过滤器对应到Redis的数据结构里面就是一个大型的位数组和几个不一样的无偏hash函数,

向布隆过滤器中添加key时,会使用多个hash函数对key进行hash,算得一个整数索引值,然后对位数组长度进行取模运算得到一个位置,每个hash函数都会算得一个不同的位置。再把位数组的这几个位置都置位1,就完成了add操作。
向布隆过滤器询问key是否存在时,只要有一个位为0,那么说明布隆过滤器中这个key不存在。如果这几个位置都是1,并不能说明这个key就一定存在,只是极有可能存在,因为这些位被置为1,可能是因为其他的key存在所致。如果这个数组比较稀疏,判断正确的概率就会很大,如果这个位数组比较拥挤,判断正确的概率就会降低。使用时不要让实际元素数量远大于初始化数量,当实际元素数量开始超出初始化数量时,应该对布隆过滤器进行重建,重新分配一个size更大的过滤器,再将所有的历史元素批量add进去(这就要求我们在其他的存储器中记录所有的历史元素)。因为error_rate不会因为数量刚一超出就急剧增加,这就给我们重建过滤器提供了较为宽松的时间。
空间占用统计
布隆过滤器的空间占用计算有一个简单的公式。布隆过滤器有两个参数,第一个是预计元素的数量n,第二个是错误率f。公式根据这两个输入得到两个输出,第一个输出是位数组的长度1,也就是需要的存储空间大小(bit),第二个输出是hash函数的最佳数量k。hash函数的数量也会直接影响到错误率,最佳的数量会有最低的错误率。
k = 0.7 * (1 / n)
f = 0.6185 ^ (1 / n)
从公式中可以看出一下结论。
1、位数组相对越长(1/n),错误率f越低,这个和直观上理解是一致的。
2、位数组相对越长(1/n),hash函数需要的最佳数量也越多,影响计算效率。
3、当一个元素平均需要1个字节(8bit)的指纹空间时(1/n=8),错误率大约为2%。
4、错误率为10%时,一个元素需要的平均指纹空间为4.792个bit,大约为5bit。
5、错误率为1%时,一个元素需要的平均指纹空间为9.585个bit,大约为10bit.
6、错误率为0.1%时,一个元素需要的平均指纹空间为14.377个big,大约为15bit。
字典的结构
在Redis中所有的key都存储在一个很大的字典中,这个字典的结构和Java中的HashMap一样,它是一维数组,是二维链表结构。第一维数组的大小总是2n,扩容一次,大小空间加倍,也就是2n+1。
scan指令返回的游标就是第一维数组的位置索引,我们将这个位置索引称为槽(slot)。如果不考虑字典的扩容缩容,直接按数组下标挨个遍历就行了。limit参数就表示需要遍历的槽位数,之所以返回的结果可能多可能少,是因为不是所有的槽位上都会挂接链表,有些槽位可能是空的,还有些槽位上挂接的链表上的元素可能会有多个,每一次遍历都会将limit数量的槽位上挂接的所有链表元素进行模式匹配过滤后,一次性返回给客户端。