
Redis对于过期键有三种清除策略:
- 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
- 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key
- 当前已用内存超过maxmemory限定时,触发主动清理策略
被动删除
只有key被操作时(如GET),REDIS才会被动检查该key是否过期,如果过期则删除之并且返回NIL。
- 这种删除策略对CPU是友好的,删除操作只有在不得不的情况下才会进行,不会对其他的expire key上浪费无谓的CPU时间。
- 但是这种策略对内存不友好,一个key已经过期,但是在它被操作之前不会被删除,仍然占据内存空间。如果有大量的过期键存在但是又很少被访问到,那会造成大量的内存空间浪费。expireIfNeeded(redisDb *db, robj *key)函数位于src/db.c。
但仅是这样是不够的,因为可能存在一些key永远不会被再次访问到,这些设置了过期时间的key也是需要在过期后被删除的,我们甚至可以将这种情况看作是一种内存泄露—-无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息。
主动删除
先说一下时间事件,对于持续运行的服务器来说, 服务器需要定期对自身的资源和状态进行必要的检查和整理, 从而让服务器维持在一个健康稳定的状态, 这类操作被统称为常规操作(cron job)
在 Redis 中, 常规操作由 redis.c/serverCron 实现, 它主要执行以下操作
- 更新服务器的各类统计信息,比如时间、内存占用、数据库占用情况等。
- 清理数据库中的过期键值对。
- 对不合理的数据库进行大小调整。
- 关闭和清理连接失效的客户端。
- 尝试进行 AOF 或 RDB 持久化操作。
- 如果服务器是主节点的话,对附属节点进行定期同步。
- 如果处于集群模式的话,对集群进行定期同步和连接测试。
Redis 将 serverCron 作为时间事件来运行, 从而确保它每隔一段时间就会自动运行一次, 又因为 serverCron 需要在 Redis 服务器运行期间一直定期运行, 所以它是一个循环时间事件: serverCron 会一直定期执行,直到服务器关闭为止。
在 Redis 2.6 版本中, 程序规定 serverCron 每秒运行 10 次, 平均每 100 毫秒运行一次。 从 Redis 2.8 开始, 用户可以通过修改 hz选项来调整 serverCron 的每秒执行次数, 具体信息请参考 redis.conf 文件中关于 hz 选项的说明也叫定时删除,这里的“定期”指的是Redis定期触发的清理策略,由位于src/redis.c的activeExpireCycle(void)函数来完成。
serverCron是由redis的事件框架驱动的定位任务,这个定时任务中会调用activeExpireCycle函数,针对每个db在限制的时间REDIS_EXPIRELOOKUPS_TIME_LIMIT内迟可能多的删除过期key,之所以要限制时间是为了防止过长时间 的阻塞影响redis的正常运行。这种主动删除策略弥补了被动删除策略在内存上的不友好。
因此,Redis会周期性的随机测试一批设置了过期时间的key并进行处理。测试到的已过期的key将被删除。典型的方式为,Redis每秒做10次如下的步骤:
- 随机测试100个设置了过期时间的key
- 删除所有发现的已过期的key
- 若删除的key超过25个则重复步骤1
这是一个基于概率的简单算法,基本的假设是抽出的样本能够代表整个key空间,redis持续清理过期的数据直至将要过期的key的百分比降到了25%以下。这也意味着在任何给定的时刻已经过期但仍占据着内存空间的key的量最多为每秒的写操作量除以4.
Redis-3.0.0中的默认值是10,代表每秒钟调用10次后台任务。
hz调大将会提高Redis主动淘汰的频率,如果你的Redis存储中包含很多冷数据占用内存过大的话,可以考虑将这个值调大,但Redis作者建议这个值不要超过100。我们实际线上将这个值调大到100,观察到CPU会增加2%左右,但对冷数据的内存释放速度确实有明显的提高(通过观察keyspace个数和used_memory大小)。
可以看出timelimit和server.hz是一个倒数的关系,也就是说hz配置越大,timelimit就越小。换句话说是每秒钟期望的主动淘汰频率越高,则每次淘汰最长占用时间就越短。这里每秒钟的最长淘汰占用时间是固定的250ms(1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/100),而淘汰频率和每次淘汰的最长时间是通过hz参数控制的。
从以上的分析看,当redis中的过期key比率没有超过25%之前,提高hz可以明显提高扫描key的最小个数。假设hz为10,则一秒内最少扫描200个key(一秒调用10次*每次最少随机取出20个key),如果hz改为100,则一秒内最少扫描2000个key;另一方面,如果过期key比率超过25%,则扫描key的个数无上限,但是cpu时间每秒钟最多占用250ms。
当REDIS运行在主从模式时,只有主结点才会执行上述这两种过期删除策略,然后把删除操作”del key”同步到从结点。
maxmemory
当前已用内存超过maxmemory限定时,触发主动清理策略
- volatile-lru:只对设置了过期时间的key进行LRU(默认值)
- allkeys-lru : 删除lru算法的key
- volatile-random:随机删除即将过期key
- allkeys-random:随机删除
- volatile-ttl : 删除即将过期的
- noeviction : 永不过期,返回错误
当mem_used内存已经超过maxmemory的设定,对于所有的读写请求,都会触发redis.c/freeMemoryIfNeeded(void)函数以清理超出的内存。注意这个清理过程是阻塞的,直到清理出足够的内存空间。所以如果在达到maxmemory并且调用方还在不断写入的情况下,可能会反复触发主动清理策略,导致请求会有一定的延迟。
清理时会根据用户配置的maxmemory-policy来做适当的清理(一般是LRU或TTL),这里的LRU或TTL策略并不是针对redis的所有key,而是以配置文件中的maxmemory-samples个key作为样本池进行抽样清理。
maxmemory-samples在redis-3.0.0中的默认配置为5,如果增加,会提高LRU或TTL的精准度,redis作者测试的结果是当这个配置为10时已经非常接近全量LRU的精准度了,并且增加maxmemory-samples会导致在主动清理时消耗更多的CPU时间,建议:
尽量不要触发maxmemory,最好在mem_used内存占用达到maxmemory的一定比例后,需要考虑调大hz以加快淘汰,或者进行集群扩容。
如果能够控制住内存,则可以不用修改maxmemory-samples配置;如果Redis本身就作为LRU cache服务(这种服务一般长时间处于maxmemory状态,由Redis自动做LRU淘汰),可以适当调大maxmemory-samples。
这里提一句,实际上redis根本就不会准确的将整个数据库中最久未被使用的键删除,而是每次从数据库中随机取5个键并删除这5个键里最久未被使用的键。上面提到的所有的随机的操作实际上都是这样的,这个5可以用过redis的配置文件中的maxmemeory-samples参数配置。
Replication link和AOF文件中的过期处理
为了获得正确的行为而不至于导致一致性问题,当一个key过期时DEL操作将被记录在AOF文件并传递到所有相关的slave。也即过期删除操作统一在master实例中进行并向下传递,而不是各salve各自掌控。这样一来便不会出现数据不一致的情形。当slave连接到master后并不能立即清理已过期的key(需要等待由master传递过来的DEL操作),slave仍需对数据集中的过期状态进行管理维护以便于在slave被提升为master会能像master一样独立的进行过期处理。
LRU原理
在一般标准的操作系统教材里,会用下面的方式来演示 LRU 原理,假设内存只能容纳3个页大小,按照 7 0 1 2 0 3 0 4 的次序访问页。假设内存按照栈的方式来描述访问时间,在上面的,是最近访问的,在下面的是,最远时间访问的,LRU就是这样工作的。
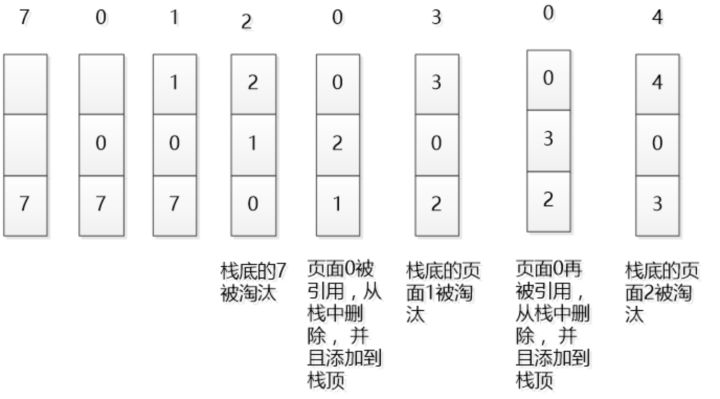
但是如果让我们自己设计一个基于 LRU 的缓存,这样设计可能问题很多,这段内存按照访问时间进行了排序,会有大量的内存拷贝操作,所以性能肯定是不能接受的。
那么如何设计一个LRU缓存,使得放入和移除都是 O(1) 的,我们需要把访问次序维护起来,但是不能通过内存中的真实排序来反应,有一种方案就是使用双向链表。
基于HashMap和双向链表实现LRU
整体的设计思路是,可以使用 HashMap 存储 key,这样可以做到 save 和 get key的时间都是 O(1),而 HashMap 的 Value 指向双向链表实现的 LRU 的 Node 节点,如图所示。
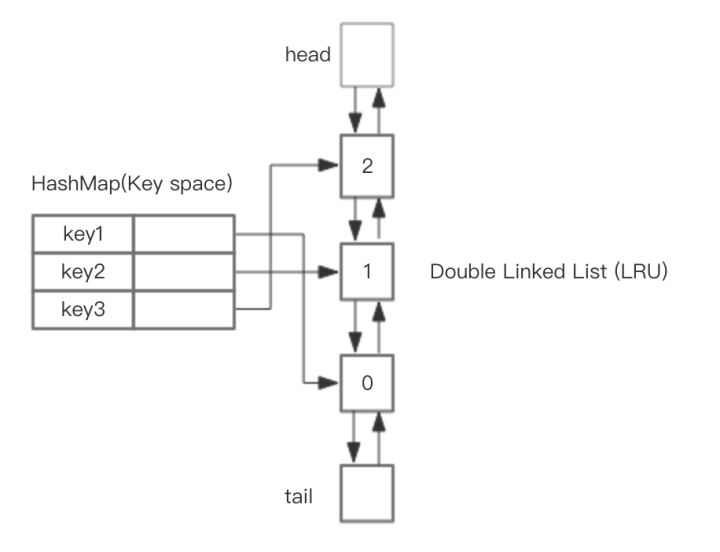
LRU 存储是基于双向链表实现的,下面的图演示了它的原理。其中 h 代表双向链表的表头,t 代表尾部。首先预先设置 LRU 的容量,如果存储满了,可以通过 O(1) 的时间淘汰掉双向链表的尾部,每次新增和访问数据,都可以通过 O(1)的效率把新的节点增加到对头,或者把已经存在的节点移动到队头。
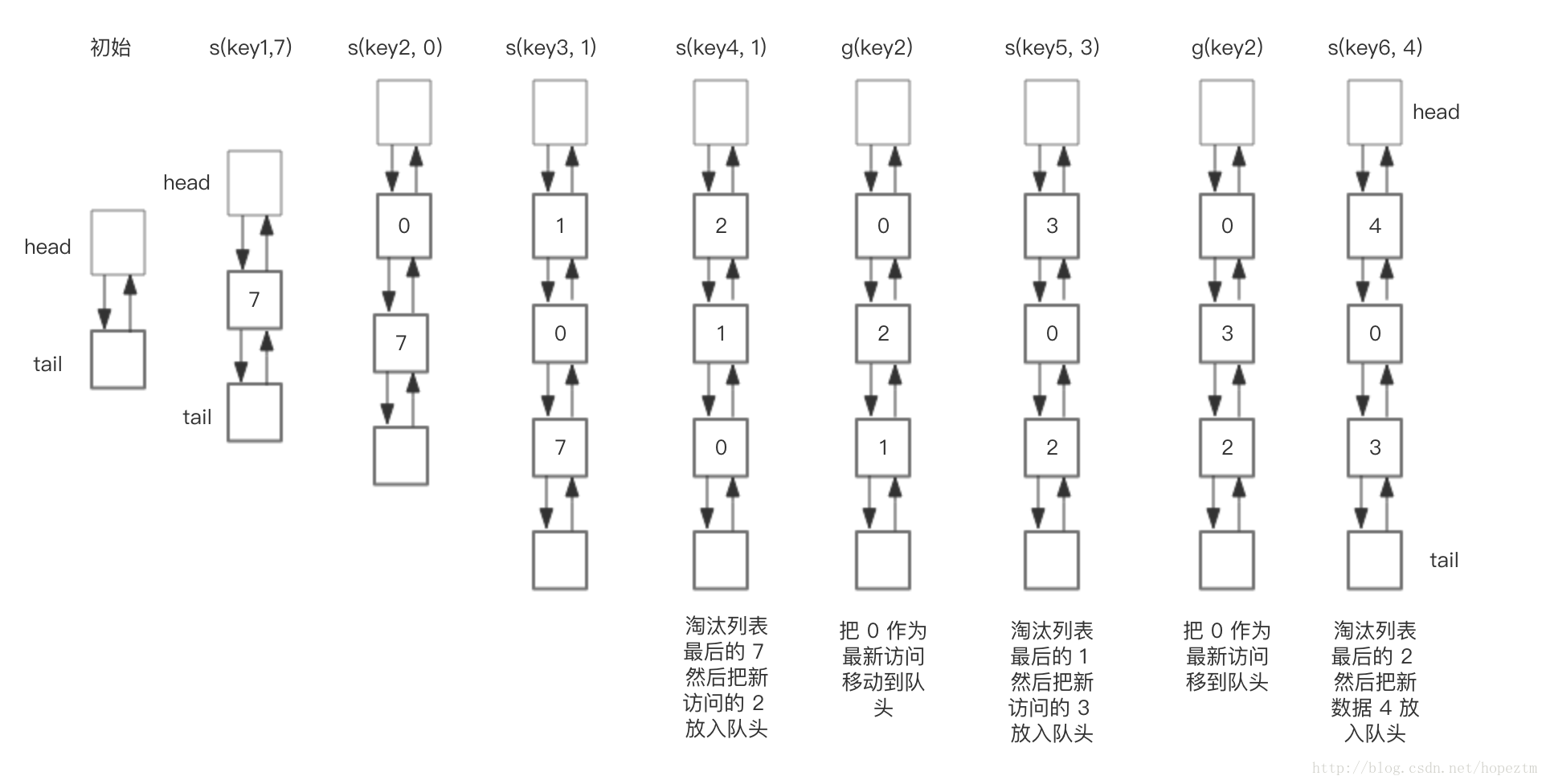
下面展示了,预设大小是 3 的,LRU存储的在存储和访问过程中的变化。为了简化图复杂度,图中没有展示 HashMap部分的变化,仅仅演示了上图 LRU 双向链表的变化。我们对这个LRU缓存的操作序列如下:
save("key1", 7)
save("key2", 0)
save("key3", 1)
save("key4", 2)
get("key2")
save("key5", 3)
get("key2")
save("key6", 4)
相应的 LRU 双向链表部分变化如下:
总结一下核心操作的步骤:
save(key, value),首先在 HashMap 找到 Key 对应的节点,如果节点存在,更新节点的值,并把这个节点移动队头。如果不存在,需要构造新的节点,并且尝试把节点塞到队头,如果LRU空间不足,则通过 tail 淘汰掉队尾的节点,同时在 HashMap 中移除 Key。
get(key),通过 HashMap 找到 LRU 链表节点,把节点插入到队头,返回缓存的值。
Redis的LRU实现
如果按照HashMap和双向链表实现,需要额外的存储存放 next 和 prev 指针,牺牲比较大的存储空间,显然是不划算的。所以Redis采用了一个近似的做法,就是随机取出若干个key,然后按照访问时间排序后,淘汰掉最不经常使用的,具体分析如下:
为了支持LRU,Redis 2.8.19中使用了一个全局的LRU时钟,server.lruclock,定义如下,
#define REDIS_LRU_BITS 24
unsigned lruclock:REDIS_LRU_BITS; /* Clock for LRU eviction */
默认的LRU时钟的分辨率是1秒,可以通过改变REDIS_LRU_CLOCK_RESOLUTION宏的值来改变,Redis会在serverCron()中调用updateLRUClock定期的更新LRU时钟,更新的频率和hz参数有关,默认为100ms一次,如下,
#define REDIS_LRU_CLOCK_MAX ((1<<REDIS_LRU_BITS)-1) /* Max value of obj->lru */
#define REDIS_LRU_CLOCK_RESOLUTION 1 /* LRU clock resolution in seconds */
void updateLRUClock(void) {
server.lruclock = (server.unixtime / REDIS_LRU_CLOCK_RESOLUTION) &
REDIS_LRU_CLOCK_MAX;
}
server.unixtime是系统当前的unix时间戳,当 lruclock 的值超出REDIS_LRU_CLOCK_MAX时,会从头开始计算,所以在计算一个key的最长没有访问时间时,可能key本身保存的lru访问时间会比当前的lrulock还要大,这个时候需要计算额外时间,如下,
/* Given an object returns the min number of seconds the object was never
* requested, using an approximated LRU algorithm. */
unsigned long estimateObjectIdleTime(robj *o) {
if (server.lruclock >= o->lru) {
return (server.lruclock - o->lru) * REDIS_LRU_CLOCK_RESOLUTION;
} else {
return ((REDIS_LRU_CLOCK_MAX - o->lru) + server.lruclock) *
REDIS_LRU_CLOCK_RESOLUTION;
}
}
Redis支持和LRU相关淘汰策略包括,
- volatile-lru 设置了过期时间的key参与近似的lru淘汰策略
- allkeys-lru 所有的key均参与近似的lru淘汰策略
当进行LRU淘汰时,Redis按如下方式进行的,
......
/* volatile-lru and allkeys-lru policy */
else if (server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_LRU ||
server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_LRU)
{
for (k = 0; k < server.maxmemory_samples; k++) {
sds thiskey;
long thisval;
robj *o;
de = dictGetRandomKey(dict);
thiskey = dictGetKey(de);
/* When policy is volatile-lru we need an additional lookup
* to locate the real key, as dict is set to db->expires. */
if (server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_LRU)
de = dictFind(db->dict, thiskey);
o = dictGetVal(de);
thisval = estimateObjectIdleTime(o);
/* Higher idle time is better candidate for deletion */
if (bestkey == NULL || thisval > bestval) {
bestkey = thiskey;
bestval = thisval;
}
}
}
......
Redis会基于server.maxmemory_samples配置选取固定数目的key,然后比较它们的lru访问时间,然后淘汰最近最久没有访问的key,maxmemory_samples的值越大,Redis的近似LRU算法就越接近于严格LRU算法,但是相应消耗也变高,对性能有一定影响,样本值默认为5。
redis过期策略
redis所有的数据结构都可以设置过期时间,时间一到,就会自动删除。
过期的key集合
redis会将每个设置了过期时间的key放入一个独立的字典中,以后会定时遍历这个字典来删除到期的key。除了定时遍历之外,还会使用惰性策略来删除过期的key。所谓惰性策略就是在客户端访问这个key的时候,redis对key的过期时间进行检查,如果过期了就立即删除。如果说定时删除是集中处理,那么惰性删除就是零散处理。
定时扫描策略
Redis设置key过期时间
Redis支持为所有类型的数据设置过期时间,对于String类型,只需要使用setex命令或者set key value EX seconds命令:
127.0.0.1:6379> SETEX a 10 sss
OK
127.0.0.1:6379> TTL a
(integer) 8
127.0.0.1:6379> TTL a
(integer) 1
127.0.0.1:6379> TTL a
(integer) -2
对于某个key重新设置值,将会清除该key目前关联的过期时间。更常见的设置过期时间方式是依靠EXPIRE/PEXPIRE命令来设置或者更新过期时间为ttl秒/毫秒,依靠 EXPIREA/PEXPIREAT命令来设置或者更新过期时间为timestamp 所指定的 秒数/毫秒数时间戳。
实际上EXPIRE、PEXPIRE、EXPIREAT三个命令的底层都是使用PEXPIREAT命令来实现的,且底层的时间进度都是毫秒。
PERSIST 命令则可以移除一个键的过期时间。
检查剩余时间需要使用TTL或者PTTL命令,非别返回秒和毫秒级别的剩余时间,它们都是通过计算键的过期时间和当前时间之间的差来实现的。
2 Redis过期key删除策略
在Redis中,内存的大小是有限的,所以为了防止内存饱和,需要实现某种键淘汰策略。主要有两种方法,一种是当Redis内存不足时所采用的内存释放策略。另一种是对过期key进行删除的策略,也可以在某种程度上释放内存。
Redis采用的默认内存释放策略是noeviction-不删除,达到最大内存时,如需更多内存(存入数据),则操作报错,内存释放策略我们之前就已经讲过了:Redis的内存淘汰策略;默认的过期key删除策略则是惰性删除+定期删除的方案;
常见的过期数据删除策略如下:
定时删除
在设置key的过期时间的同时,创建一个定时器,让定时器在key的过期时间来临时,立即执行对key的删除操作;
定时删除操作对于内存来说是友好的,内存不需要操作,而是通过使用定时器,可以保证尽快的将过期key删除,但是对于CPU来说不是友好的,如果过期key比较多的话,起的定时器也会比较多,每一个定时器会占用到CPU的资源;
惰性删除
不管key有没有过期都不主动删除,但是每次从键空间中获取键值时,都检查取得的key的过期时间,如果过期的话,返回null,然后删除key即可;
惰性操作对于CPU来说是友好的,过期key只有在程序读取时判断是否过期才删除掉,而且也只会删除这一个过期键,但是对于内存来说是不友好的,如果多个key都已经过期了,而这些key又恰好没有被访问,那么这部分的内存就都不会被释放出来;
定期删除
每隔一段时间,程序就对数据库进行一次检查,删除掉过期key;
定期删除是上面两种方案的折中方案,每隔一段时间来删除过期key,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响,除此之外,还有效的减少内存的浪费;但是该策略的难点在于间隔时长,这个需要根据自身业务情况来进行设置,并且可能由于扫描不及时,导致过期的key也被返回。
目前,Redis采用的是惰性删除+定期删除的方案。Redis 的定期扫描只会扫描设置了过期时间的键,Redis 通过一个单独的过期字典expires(可以看作是 hash 表)来保存设置了过期时间的数据过期的时间,所以不会出现扫描所有键的情况,即使如此,redis也是默认是每隔 100ms 就随机抽取过期字典中的 key,检查其是否过期,如果过期就删除。如果不定时随机抽查而是全部扫描,那么将可能有很长的时间导致服务对外不可用,这是无异于一场灾难。
由于是随机扫描,那么对于已经过期但没有被扫描到的key怎么办呢,没关系,还有惰性删除,在获取某个 key 的时候,Redis 会检查一下 ,这个 key 如果设置了过期时间那么是否过期了?如果过期了此时就会删除,返回null。
过期字典dict的key是一个指针,这个指针指向键空间中的某个key对象(也即是某个数据库键)。过期字典的值是一个long long类型的整数,这个整数保存了key所指向的数据库key的过期时间——一个毫秒精度的UNIX时间戳。在实际中,键空间的key和过期字典的key都指向同一个key对象,所以不会出现任何重复对象,也不会浪费任何空间。
typedef struct redisDb {
dict *dict; //键空间,存放所有的key-value键值对
dict *expires; //设置了过期时间的key到它的过期时间的键值对
} redisDb;
PERSIST命令在过期字典中查找给定的key,并解除key和值(过期时间)在过期字典中的关联。