
1. 在Springboot加载spring.factories文件时使用的cache
private static final Map<ClassLoader, MultiValueMap<String, String>> cache = new ConcurrentReferenceHashMap<>();
2. ConcurrentReferenceHashMap结构
-6e297a13a9974203a9f7d566df2e9a6e.png)
大体上和ConcurrentHashMap结构是保持一致的,不同的就是ConcurrentReferenceHashMap中维护了一个Reference的引用。该引用默认是软引用,软引用只能在JVM在OutOfMemoryException异常之前被垃圾回收器回收。
3. ConcurrentReferenceHashMap中关键的组件介绍:
(1)、Segment(最上一级的数组):在ConcurrentReferenceHashMap是作为一个数组存在,每个Segment都是一个ReentrantLock锁,每个Segment都持有一个ReferenceManager的引用,是驱动put的主要类。
(2)、ReferenceManager:该类主要是为了在重新生成结构时,作为触发时机。并且会通过ReferenceManager来获取所有需要被回收的对象,然后从Reference的数组中移除。主要是依赖ReferenceQueue这个队列,如果JVM有需要回收的对象时会放入该队列。每个ReferenceManager都负责管理Segment下所属的对象,感知它们是否处于被GC回收器回收阶段。ReferenceManager通过工厂模式来创建SoftEntryReference(软引用)和WeakEntryReference(弱引用)
(3)、Reference(最下一级的数组):在Segment下持有一个Entry引用,该Reference有两种类型SoftEntryReference(软引用)和WeakEntryReference(弱引用)其中SoftEntryReference该类型的引用会存活到JVM报OutOfMemoryException异常之前。WeakEntryReference该类型的引用只会存活到下次GC之前。该类型的数据是真正存放Map数据的地方。
4.存入数据逻辑
@Nullable
private V put(@Nullable final K key, @Nullable final V value, final boolean overwriteExisting) {
return doTask(key, new Task<V>(TaskOption.RESTRUCTURE_BEFORE, TaskOption.RESIZE) {
@Override
@Nullable
protected V execute(@Nullable Reference<K, V> ref, @Nullable Entry<K, V> entry, @Nullable Entries<V> entries) {
if (entry != null) {
V oldValue = entry.getValue();
if (overwriteExisting) {
entry.setValue(value);
}
return oldValue;
}
Assert.state(entries != null, "No entries segment");
entries.add(value);
return null;
}
});
}
以上代码是存入数据逻辑的开始:
接下来进入到doTask中:
@Nullable
private <T> T doTask(@Nullable Object key, Task<T> task) {
int hash = getHash(key);
return getSegmentForHash(hash).doTask(hash, key, task);
}
首先会先计算key的hash值,并根据hash值来获取Segment,然后通过Segment的doTask来执行真正的put操作。这里用到取index的算法是这样的:
(hash >>> (32 - this.shift)) & (this.segments.length - 1)
Segment中的doTask代码如下:
@Nullable
public <T> T doTask(final int hash, @Nullable final Object key, final Task<T> task) {
boolean resize = task.hasOption(TaskOption.RESIZE);
if (task.hasOption(TaskOption.RESTRUCTURE_BEFORE)) {
restructureIfNecessary(resize);
}
if (task.hasOption(TaskOption.SKIP_IF_EMPTY) && this.count.get() == 0) {
return task.execute(null, null, null);
}
lock();
try {
final int index = getIndex(hash, this.references);
final Reference<K, V> head = this.references[index];
Reference<K, V> ref = findInChain(head, key, hash);
Entry<K, V> entry = (ref != null ? ref.get() : null);
Entries<V> entries = value -> {
@SuppressWarnings("unchecked")
Entry<K, V> newEntry = new Entry<>((K) key, value);
Reference<K, V> newReference = Segment.this.referenceManager.createReference(newEntry, hash, head);
Segment.this.references[index] = newReference;
Segment.this.count.incrementAndGet();
};
return task.execute(ref, entry, entries);
}
finally {
unlock();
if(task.hasOption(TaskOption.RESTRUCTURE_AFTER)) {
restructureIfNecessary(resize);
}
}
}
首先判断Task中是否存在RESIZE操作,上面put方法创建的Task操作时放入了TaskOption.RESTRUCTURE_BEFORE和TaskOption.RESIZE,所以进入Segment的doTask方法的时候会执行restructureIfNecessary,这是一个扩容或缩容的操作,后面详细再介绍该操作。
执行完变更链表结构后,判断如果数组内的数据为0并且SKIP_IF_EMPTY那么直接向Map中插入Null值后抛出异常,具体为什么要这么操作,待分析。
接下来执行加锁操作,通过key的hash值找到映射到Segment数组的位置,并通过如下逻辑找到key相同的一个Reference
@Nullable
private Reference<K, V> findInChain(Reference<K, V> ref, @Nullable Object key, int hash) {
Reference<K, V> currRef = ref;
while (currRef != null) {
if (currRef.getHash() == hash) {
Entry<K, V> entry = currRef.get();
if (entry != null) {
K entryKey = entry.getKey();
if (ObjectUtils.nullSafeEquals(entryKey, key)) {
return currRef;
}
}
}
currRef = currRef.getNext();
}
return null;
}
并临时创建一个Entries对象,这个对象主要的作用就是向链表头增加一个Entry并将指针指向原来的head,将count+1。具体的添加操作委托给了最初put的task对象的execute方法,这个方法执行的逻辑就是如果从原链表中存在找到Entry不为空,那么就更新值,否则就创建一个Entry并保存。
以上就是ConcurrentReferenceHashMap的put操作的流程。
5.删除数据逻辑
与增加数据逻辑相似:
@Override
@Nullable
public V remove(Object key) {
return doTask(key, new Task<V>(TaskOption.RESTRUCTURE_AFTER, TaskOption.SKIP_IF_EMPTY) {
@Override
@Nullable
protected V execute(@Nullable Reference<K, V> ref, @Nullable Entry<K, V> entry) {
if (entry != null) {
if (ref != null) {
ref.release();
}
return entry.value;
}
return null;
}
});
}
主要的实现逻辑也是委托doTask方法,在创建Task的实例的时候传入了
TaskOption.RESTRUCTURE_AFTER, TaskOption.SKIP_IF_EMPTY
意味着执行操作之后重新计算各个Entry也就是reference在数组中的位置。
前面逻辑都是一样的唯一不同的是task的执行逻辑变化了。
找到Entry就通过ref的release操作来手动释放这个引用,这里面需要注意手动释放的逻辑。
@Override
public void release() {
enqueue();
clear();
}
enqueue方法执行的操作是将该Reference放入到F-Queue中,告知收集器GC掉该对象,clear方法就是将Reference对象赋null值。之后会执行restructureIfNecessary(resize);操作,该操作会从F-Queue中获取对象,并重新计算存活下来的对象在数据中的位置。
这里面的代码逻辑可以借鉴下,写的非常优雅。
主要是对同一逻辑的操作封装到一起,不同的逻辑的地方采用了使用不同的对象来执行不同的逻辑操作。
6.替换数据逻辑
替换数据逻辑也是一样的:
@Override
public boolean replace(K key, final V oldValue, final V newValue) {
Boolean result = doTask(key, new Task<Boolean>(TaskOption.RESTRUCTURE_BEFORE, TaskOption.SKIP_IF_EMPTY) {
@Override
protected Boolean execute(@Nullable Reference<K, V> ref, @Nullable Entry<K, V> entry) {
if (entry != null && ObjectUtils.nullSafeEquals(entry.getValue(), oldValue)) {
entry.setValue(newValue);
return true;
}
return false;
}
});
return (result == Boolean.TRUE);
}
前面还是复用doTask的代码逻辑,只是在执行时候,会判断是否查找到了Entry,如果找到了并且oldValue和找到的Entry的value相等,那么就替换value后返回。
7.查询数据逻辑
入口如下:
@Override
@Nullable
public V get(@Nullable Object key) {
Reference<K, V> ref = getReference(key, Restructure.WHEN_NECESSARY);
Entry<K, V> entry = (ref != null ? ref.get() : null);
return (entry != null ? entry.getValue() : null);
}
具体获取数据的逻辑是在getReference中执行的:
@Nullable
protected final Reference<K, V> getReference(@Nullable Object key, Restructure restructure) {
int hash = getHash(key);
return getSegmentForHash(hash).getReference(key, hash, restructure);
}
这里在通过key的hash找到对应的Segment后,通过Segment的getReference方法来查询数据:
@Nullable
public Reference<K, V> getReference(@Nullable Object key, int hash, Restructure restructure) {
if (restructure == Restructure.WHEN_NECESSARY) {
restructureIfNecessary(false);
}
if (this.count.get() == 0) {
return null;
}
// Use a local copy to protect against other threads writing
Reference<K, V>[] references = this.references;
int index = getIndex(hash, references);
Reference<K, V> head = references[index];
return findInChain(head, key, hash);
}
首先还是会重新计算各个Entry也就是reference在数组中的位置,之后通过计算index的值来查找是否存在这个Reference。
8.restructure逻辑
最后讲下restructure逻辑:这个逻辑的出现是当Map扩容和缩容的时候触发的,扩容是向Map中放入数据,而缩容则因为该Map中的引用被销毁了。
代码如下:
protected final void restructureIfNecessary(boolean allowResize) {
int currCount = this.count.get();
boolean needsResize = allowResize && (currCount > 0 && currCount >= this.resizeThreshold);
Reference<K, V> ref = this.referenceManager.pollForPurge();
if (ref != null || (needsResize)) {
restructure(allowResize, ref);
}
}
private void restructure(boolean allowResize, @Nullable Reference<K, V> ref) {
boolean needsResize;
lock();
try {
int countAfterRestructure = this.count.get();
Set<Reference<K, V>> toPurge = Collections.emptySet();
if (ref != null) {
toPurge = new HashSet<>();
while (ref != null) {
toPurge.add(ref);
ref = this.referenceManager.pollForPurge();
}
}
countAfterRestructure -= toPurge.size();
// Recalculate taking into account count inside lock and items that
// will be purged
needsResize = (countAfterRestructure > 0 && countAfterRestructure >= this.resizeThreshold);
boolean resizing = false;
int restructureSize = this.references.length;
if (allowResize && needsResize && restructureSize < MAXIMUM_SEGMENT_SIZE) {
restructureSize <<= 1;
resizing = true;
}
// Either create a new table or reuse the existing one
Reference<K, V>[] restructured =
(resizing ? createReferenceArray(restructureSize) : this.references);
// Restructure
for (int i = 0; i < this.references.length; i++) {
ref = this.references[i];
if (!resizing) {
restructured[i] = null;
}
while (ref != null) {
if (!toPurge.contains(ref)) {
Entry<K, V> entry = ref.get();
if (entry != null) {
int index = getIndex(ref.getHash(), restructured);
restructured[index] = this.referenceManager.createReference(
entry, ref.getHash(), restructured[index]);
}
}
ref = ref.getNext();
}
}
// Replace volatile members
if (resizing) {
this.references = restructured;
this.resizeThreshold = (int) (this.references.length * getLoadFactor());
}
this.count.set(Math.max(countAfterRestructure, 0));
}
finally {
unlock();
}
}
强调下,这里的扩容或缩容操作都是基于Segment的。首先加锁,获取操作之前数据的容量,然后创建个Set用于保存需要处理掉的对象,如果没有那么这个Set里面就是空,如果是空的话,那么当前执行的就会是扩容操作。这里简单的就是将Reference数据的大小扩大为原来的2倍。并执行重新计算每个Entry来Segment数组中的位置。如果这个对象是即将被GC的对象那么就忽略,继续计算下一个对象的位置。计算完成后用新的Reference<K, V>[]对象覆盖原来的对象的地址,注意这个操作是原子的,因为被修饰为volatile。
private volatile Reference<K, V>[] references;
最后附上ConcurrentReferenceHashMap中的doTask操作中的逻辑图:
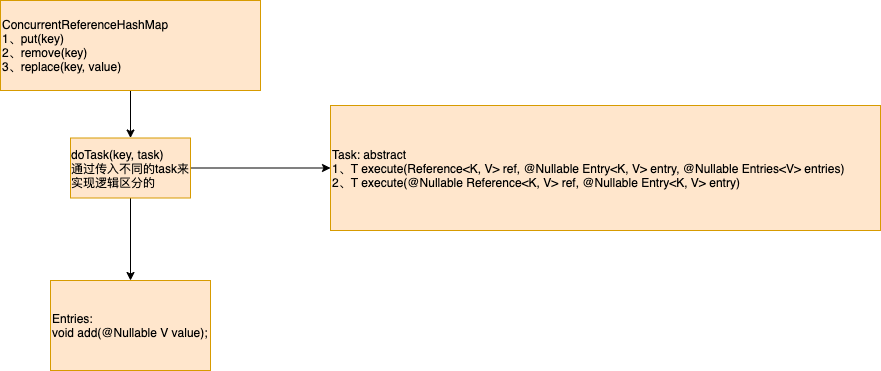
详细介绍下doTask的操作:
主体逻辑和加锁是在doTask中执行的,具体的add操作是委托给Entries来执行的,remove操作是委托在Task的execute中执行的。
doTask的主要逻辑如下:
1、在执行操作前restructure
2、加锁
3、执行具体操作,上面已经讲了。
4、解锁
5、在执行操作后restructure