
1 联合索引
1.1联合索引简介
上篇叙述的主键索引和辅助索引都是单列索引,但遇到多条件查询时,不可避免会使用到多列索引,又叫联合索引或组合索引。单列索引的键值数量为1,联合索引键值数量大于等于2。【MySQL中的索引(一) 】
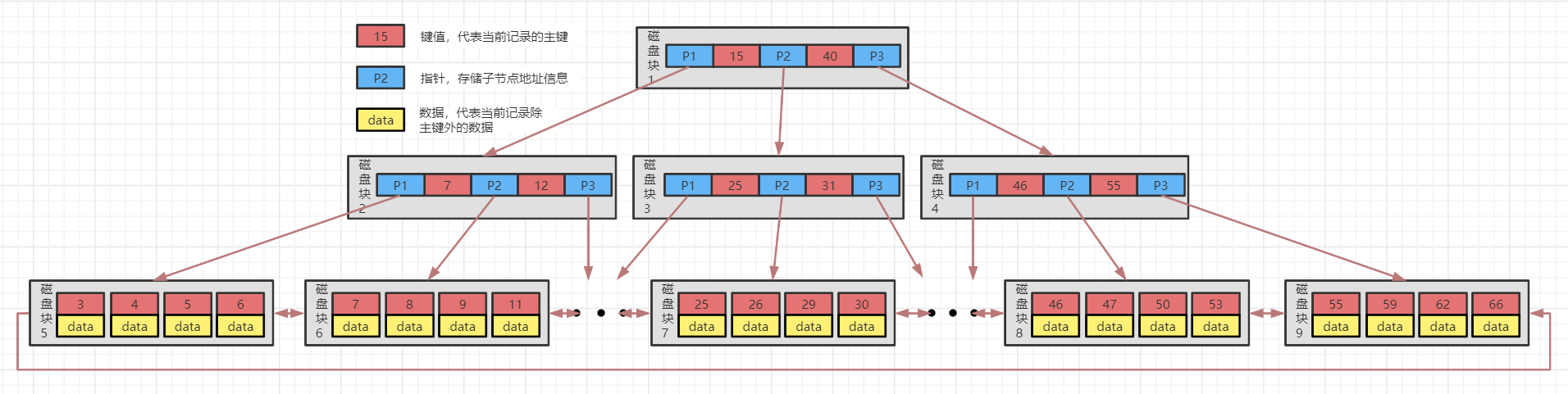
无论是单列索引还是联合索引,在MySQL中,数据结构均是B+树,如下图。
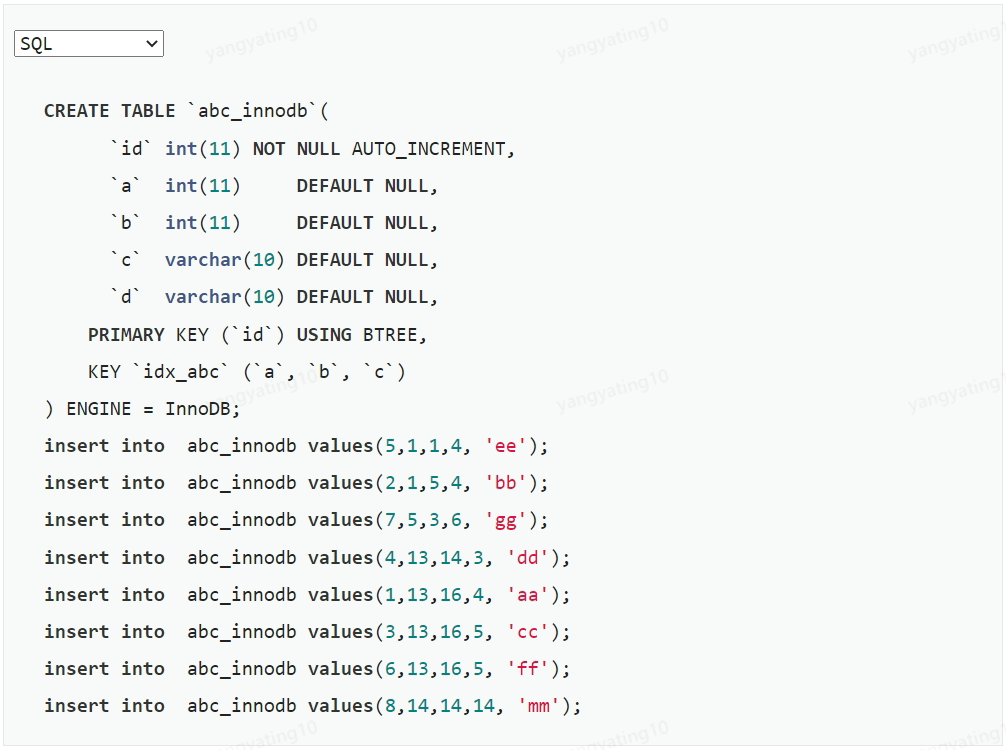
下面创建一个联合索引并插入三条语句:
插入数据后索引如图:
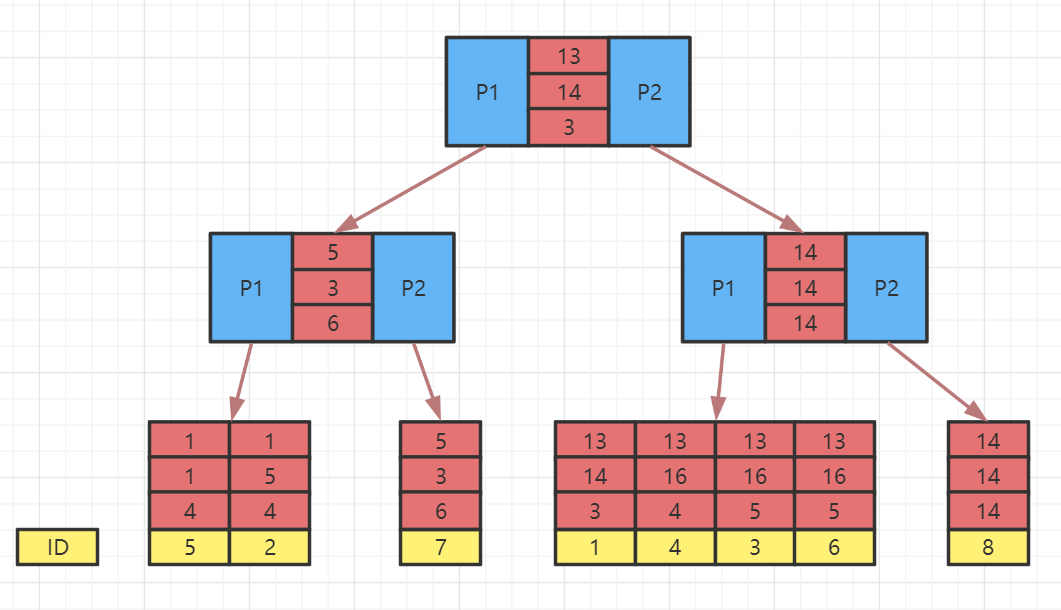
在联合索引树中,最底层的叶子节点按照第一列a列从左到右递增排列,但是b列和c列是无序的,b列只有在a列值相等的情况下小范围内递增有序,而c列只能在a,b两列相等的情况下小范围内递增有序。
通过select * from abc_innodb where a = 13 and b = 16 and c = 4;来说明联合索引的查询过程,如下图:
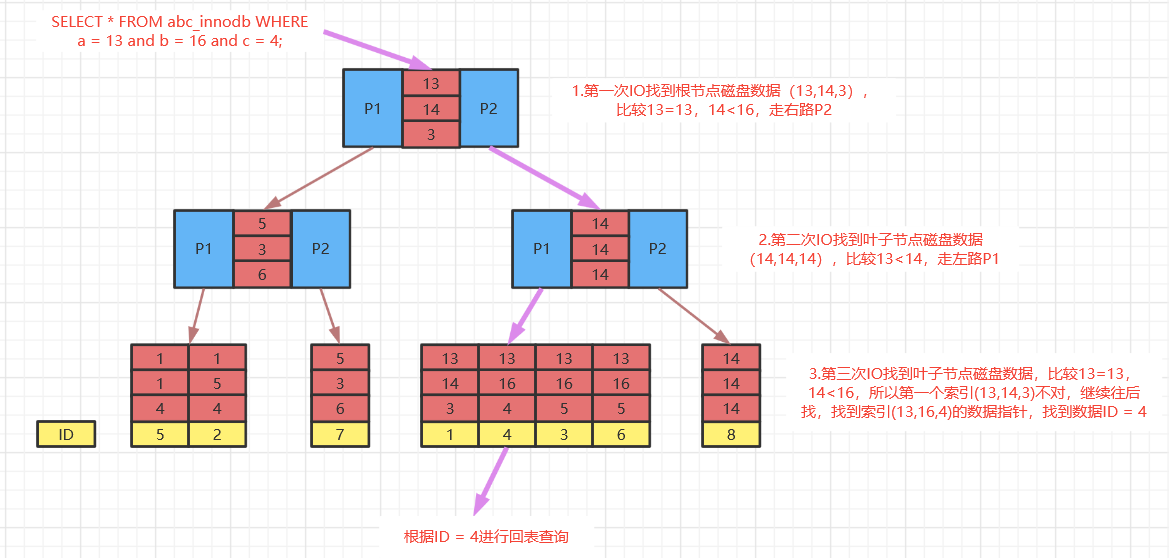
就像上面的查询,B+树会先比较a列来确定下一步应该搜索的方向,往左还是往右。如果a列相同再比较b列。但是如果查询条件没有a列,B+树就不知道第一步应该从哪个节点查起。
可以说创建的idx_abc(a,b,c)索引,相当于创建了(a)、(a,b)(a,b,c)三个索引。
1.2 最左匹配原则
在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。 对于刚刚建立的abc_innodb这个表可以进行进行一些实践:
1.2.1 索引生效
explain select * from abc_innodb where b = 1;

这里是全表扫描,没有用到索引,同时只使用c或者只使用d作为查询条件也不会使用到索引; explain select * from abc_innodb where a = 1 and b = 1;

命中了索引,且是联合索引,说明符合最左前缀规则。
1.2.2 使用and联合查询
explain select * from abc_innodb where b = 1 and a = 1 and c = 4;

在执行sql的时候,优化器会帮我们调整where后b,a,c的顺序和索引一致,让我们用上索引,所以and情况下,只要有索引顺序第一个字段存在,就可以命中索引,如上图,否则就无法命中索引,如下图:
explain select * from abc_innodb where b = 1 and c = 4;

1.2.3 范围查询
explain select * from abc_innodb where id > 2;

表示范围查询,没有命中索引。
explain select * from abc_innodb where id = 2 and b > 1;

该条语句命中了索引。当遇到范围查询(>、<、between、like)就会停止匹配,但是停止匹配的是使用范围的字段,比如第一条sql中的id>2,第二条sql中的最终索引匹配终止在b字段,但是前面的id字段还可以使用索引。
最左前缀匹配原则和联合索引的索引存储结构和检索方式是有关系的。联合索引的最左前缀匹配原则:使用联合索引查询时,MySQL会一直向右匹配直至遇到范围查询(>、<、between、like)就停止匹配。
2 覆盖索引
2.1 回表
首先创建一个表,然后创建索引,然后插入数据,sql如下:

此时,我们的索引树有两棵,如图:
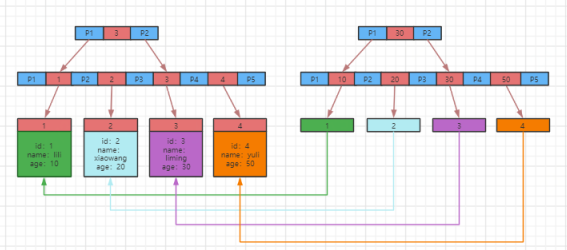
根据叶子节点的内容,索引的类型分为主键索引和非主键索引;
上图左边的是主键索引,叶子节点存储的是整行数据,右边非主键索引的叶子节点存储的是主键索引的中的一条数据,所以非主键索引也叫做二级索引。
select * from T_table where id = 3; select * from T_table where age = 30;
第一条语句可以直接使用主键索引进行查询,通过主键索引可以直接拿到这一行的数据。 第二条语句是通过非聚集索引查询数据,先通过非主键索引查询主键索引,然后再搜索一次找到聚集索引的行数据。 第二种其实就是回表操作,也就是说非主键索引比主键索引多查询一棵树。
2.2 覆盖索引
上面提到,我们使用非聚集索引的时候,需要多查询一个树,这样其实造成了效率会比较低,所以在什么情况下可以避免回表操作。我们还是用刚才的语句进行修改:
select id from T_table where age = 30;
这条语句是根据上述的回表语句的变形,由于这次查询的id已经是存储在索引树上了,所以可以直接使用索引查询,不需要回表操作。
覆盖索引并不是说是索引结构,覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到主键值,相当于获取数据还需要再根据主键查询主键索引再获取到数据。但是试想下这么一种情况,在上面T_table表中的索引查询时,如果只需要id字段,那就意味着我们查询到联合索引的叶子节点就可以直接返回了,而不需要回表。这种情况就是覆盖索引。在这个查询中,索引age已经覆盖了查询请求,即索引覆盖。
3 总结
联合索引具备以下优势:
减少开销。建一个联合索引(a,b,c),实际相当于建了(a),(a,b),(a,b,c)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销。
覆盖索引。对联合索引(a,b,c),如果有如下的sql: select a,b,c from test where a=1 and b=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这大大减少io操作,提高查询性能。
效率高。索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select from table where a=1 and b=2 and c=3,假设假设每个条件可以筛选出10%的数据,如果只有单列索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合b=2 and c= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10%*10%=1w,效率大大提升。